Schema 解析
Schema 定义了 Collection 的数据结构。在创建 Collection 之前,您需要设计其 Schema。本页面帮助您了解 Collection Schema 并设计一个示例 Schema。
概述
在 Zilliz Cloud 上,Collection Schema 类似于关系数据库中的表,它定义了 Zilliz Cloud 如何在 Collection 中组织数据。
一个设计良好的 Schema 至关重要,因为它抽象了数据模型并决定您是否能够通过搜索实现业务目标。此外,由于插入到 Collection 中的每一行数据都必须遵循 Schema,它有助于维护数据一致性和长期质量。从技术角度来看,定义良好的 Schema 导致良好组织的列数据存储和更清洁的索引结构,提升搜索性能。
Collection Schema 有一个主键、最多四个向量字段和若干标量字段。下图说明了如何将一篇文章映射到 Schema 字段列表。
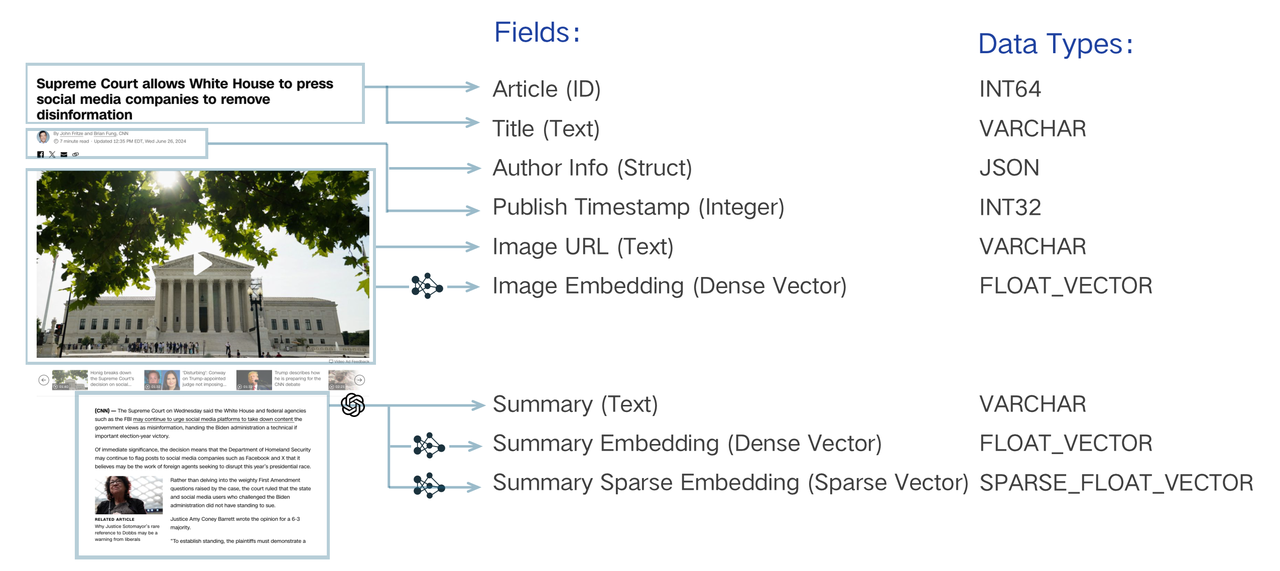
搜索系统的数据模型设计涉及分析业务需求并将信息抽象为 Schema 表达的数据模型。例如,搜索一段文本必须通过"embedding"将文字字符串转换为向量并启用向量搜索来"索引"。除了这个基本要求外,可能还需要存储其他属性,如发布时间戳和作者。这些元数据允许通过过滤来优化语义搜索,仅返回在特定日期之后发布或由特定作者发布的文本。您还可以检索这些标量与主文本一起在应用程序中渲染搜索结果。应为每个文本片段分配一个唯一标识符来组织这些文本片段,表示为整数或字符串。这些元素对于实现复杂的搜索逻辑至关重要。
请参阅 Schema 设计实践 了解如何制作设计良好的 Schema。
创建 Schema
以下代码片段演示了如何创建 Schema。
from pymilvus import MilvusClient, DataType
schema = MilvusClient.create_schema()
import io.milvus.v2.service.collection.request.CreateCollectionReq;
CreateCollectionReq.CollectionSchema schema = client.createSchema();
import { MilvusClient, DataType } from "@zilliz/milvus2-sdk-node";
const schema = []
import "github.com/milvus-io/milvus/client/v2/entity"
schema := entity.NewSchema()
export schema='{
"fields": []
}'
添加主字段
Collection 中的主字段唯一标识一个实体。它只接受 Int64 或 VarChar 值。以下代码片段演示了如何添加主字段。
schema.add_field(
field_name="my_id",
datatype=DataType.INT64,
is_primary=True,
auto_id=False,
)
import io.milvus.v2.common.DataType;
import io.milvus.v2.service.collection.request.AddFieldReq;
schema.addField(AddFieldReq.builder()
.fieldName("my_id")
.dataType(DataType.Int64)
.isPrimaryKey(true)
.autoID(false)
.build());
schema.push({
name: "my_id",
data_type: DataType.Int64,
is_primary_key: true,
autoID: false
});
schema.WithField(entity.NewField().WithName("my_id").
WithDataType(entity.FieldTypeInt64).
WithIsPrimaryKey(true).
WithIsAutoID(false),
)
export primaryField='{
"fieldName": "my_id",
"dataType": "Int64",
"isPrimary": true
}'
export schema='{
\"autoID\": false,
\"fields\": [
$primaryField
]
}'
添加字段时,您可以通过将其 is_primary 属性设置为 True 来明确说明该字段为主字段。主字段默认接受 Int64 值。在这种情况下,主字段值应该是类似 12345 的整数。如果您选择在主字段中使用 VarChar 值,则值应该是类似 my_entity_1234 的字符串。
您还可以将 autoId 属性设置为 True,使 Zilliz Cloud 在数据插入时自动分配主字段值。
详情请参阅 主字段和 AutoId。
添加向量字段
向量字段接受各种稀疏和密集向量 embedding。在 Zilliz Cloud 上,您可以向 Collection 添加四个向量字段。以下代码片段演示了如何添加向量字段。
schema.add_field(
field_name="my_vector",
datatype=DataType.FLOAT_VECTOR,
dim=5
)
schema.addField(AddFieldReq.builder()
.fieldName("my_vector")
.dataType(DataType.FloatVector)
.dimension(5)
.build());
schema.push({
name: "my_vector",
data_type: DataType.FloatVector,
dim: 5
});
schema.WithField(entity.NewField().WithName("my_vector").
WithDataType(entity.FieldTypeFloatVector).
WithDim(5),
)
export vectorField='{
"fieldName": "my_vector",
"dataType": "FloatVector",
"elementTypeParams": {
"dim": 5
}
}'
export schema="{
\"autoID\": false,
\"fields\": [
$primaryField,
$vectorField
]
}"
上述代码片段中的 dim 参数表示向量字段中存储的向量 embedding 的维度。FLOAT_VECTOR 值表示向量字段存储一个32位浮点数列表,通常用于表示反对数。除此之外,Zilliz Cloud 还支持以下类型的向量 embedding:
-
FLOAT16_VECTOR此类型的向量字段存储16位半精度浮点数列表,通常应用于内存或带宽受限的深度学习或基于GPU的计算场景。
-
BFLOAT16_VECTOR此类型的向量字段存储16位浮点数列表,具有降低的精度但与Float32相同的指数范围。这种数据类型在深度学习场景中常用,因为它能减少内存使用量而不会显著影响准确性。
-
BINARY_VECTOR此类型的向量字段存储0和1的列表。它们作为紧凑特征,用于表示图像处理和信息检索场景中的数据。
-
SPARSE_FLOAT_VECTOR此类型的向量字段存储非零数字列表及其序列号来表示 sparse vector embedding。
添加标量字段
在常见情况下,您可以使用标量字段来存储 Milvus 中存储的向量 embedding 的元数据,并进行带有元数据过滤的 ANN 搜索,以提高搜索结果的正确性。Zilliz Cloud 支持多种标量字段类型,包括 VarChar、Boolean、Int、Float、Double、Array 和 JSON。
添加字符串字段
在 Milvus 中,您可以使用 VarChar 字段来存储字符串。有关 VarChar 字段的更多信息,请参阅 字符串字段。
schema.add_field(
field_name="my_varchar",
datatype=DataType.VARCHAR,
max_length=512
)
schema.addField(AddFieldReq.builder()
.fieldName("my_varchar")
.dataType(DataType.VarChar)
.maxLength(512)
.build());
schema.push({
name: "my_varchar",
data_type: DataType.VarChar,
# highlight-next-line
max_length: 512
});
schema.WithField(entity.NewField().WithName("my_varchar").
WithDataType(entity.FieldTypeVarChar).
WithMaxLength(512),
)
export varCharField='{
"fieldName": "my_varchar",
"dataType": "VarChar",
"elementTypeParams": {
"max_length": 512
}
}'
export schema="{
\"autoID\": false,
\"fields\": [
$primaryField,
$vectorField,
$varCharField
]
}"
添加数字字段
Milvus 支持的数字类型有 Int8、Int16、Int32、Int64、Float 和 Double。有关数字字段的更多信息,请参阅 数字字段。
schema.add_field(
field_name="my_int64",
datatype=DataType.INT64,
)
schema.addField(AddFieldReq.builder()
.fieldName("my_int64")
.dataType(DataType.Int64)
.build());
schema.push({
name: "my_int64",
data_type: DataType.Int64,
});
schema.WithField(entity.NewField().WithName("my_int64").
WithDataType(entity.FieldTypeInt64),
)
export int64Field='{
"fieldName": "my_int64",
"dataType": "Int64"
}'
export schema="{
\"autoID\": false,
\"fields\": [
$primaryField,
$vectorField,
$varCharField,
$int64Field
]
}"
添加布尔字段
Milvus 支持布尔字段。以下代码片段演示了如何添加布尔字段。
schema.add_field(
field_name="my_bool",
datatype=DataType.BOOL,
)
schema.addField(AddFieldReq.builder()
.fieldName("my_bool")
.dataType(DataType.Bool)
.build());
schema.push({
name: "my_bool",
data_type: DataType.Boolean,
});
schema.WithField(entity.NewField().WithName("my_bool").
WithDataType(entity.FieldTypeBool),
)
export boolField='{
"fieldName": "my_bool",
"dataType": "Boolean"
}'
export schema="{
\"autoID\": false,
\"fields\": [
$primaryField,
$vectorField,
$varCharField,
$int64Field,
$boolField
]
}"
添加 JSON 字段
JSON 字段通常存储半结构化的 JSON 数据。有关 JSON 字段的更多信息,请参阅 JSON 字段。
schema.add_field(
field_name="my_json",
datatype=DataType.JSON,
)
schema.addField(AddFieldReq.builder()
.fieldName("my_json")
.dataType(DataType.JSON)
.build());
schema.push({
name: "my_json",
data_type: DataType.JSON,
});
schema.WithField(entity.NewField().WithName("my_json").
WithDataType(entity.FieldTypeJSON),
)
export jsonField='{
"fieldName": "my_json",
"dataType": "JSON"
}'
export schema="{
\"autoID\": false,
\"fields\": [
$primaryField,
$vectorField,
$varCharField,
$int64Field,
$boolField,
$jsonField
]
}"
添加数组字段
数组字段存储元素列表。数组字段中所有元素的数据类型应该相同。有关数组字段的更多信息,请参阅 数组字段。
schema.add_field(
field_name="my_array",
datatype=DataType.ARRAY,
element_type=DataType.VARCHAR,
max_capacity=5,
max_length=512,
)
schema.addField(AddFieldReq.builder()
.fieldName("my_array")
.dataType(DataType.Array)
.elementType(DataType.VarChar)
.maxCapacity(5)
.maxLength(512)
.build());
schema.push({
name: "my_array",
data_type: DataType.Array,
element_type: DataType.VarChar,
max_capacity: 5,
max_length: 512
});
schema.WithField(entity.NewField().WithName("my_array").
WithDataType(entity.FieldTypeArray).
WithElementType(entity.FieldTypeInt64).
WithMaxLength(512).
WithMaxCapacity(5),
)
export arrayField='{
"fieldName": "my_array",
"dataType": "Array",
"elementDataType": "VarChar",
"elementTypeParams": {
"max_length": 512
}
}'
export schema="{
\"autoID\": false,
\"fields\": [
$primaryField,
$vectorField,
$varCharField,
$int64Field,
$boolField,
$jsonField,
$arrayField
]
}"