Schema 设计实践
信息检索(IR)系统,也称为搜索引擎,对于各种 AI 应用(如检索增强生成(RAG)、图像搜索和产品推荐)至关重要。开发 IR 系统的第一步是设计数据模型,这涉及分析业务需求、确定如何组织信息以及索引数据以使其语义可搜索。
Milvus 支持通过 collection schema 定义数据模型。Collection 组织非结构化数据(如文本和图像)及其向量表示,包括用于语义搜索的各种精度的密集和稀疏向量。此外,Milvus 支持存储和过滤称为"Scalar"的非向量数据类型。Scalar 类型包括 BOOL、INT8/16/32/64、FLOAT/DOUBLE、VARCHAR、JSON 和 Array。
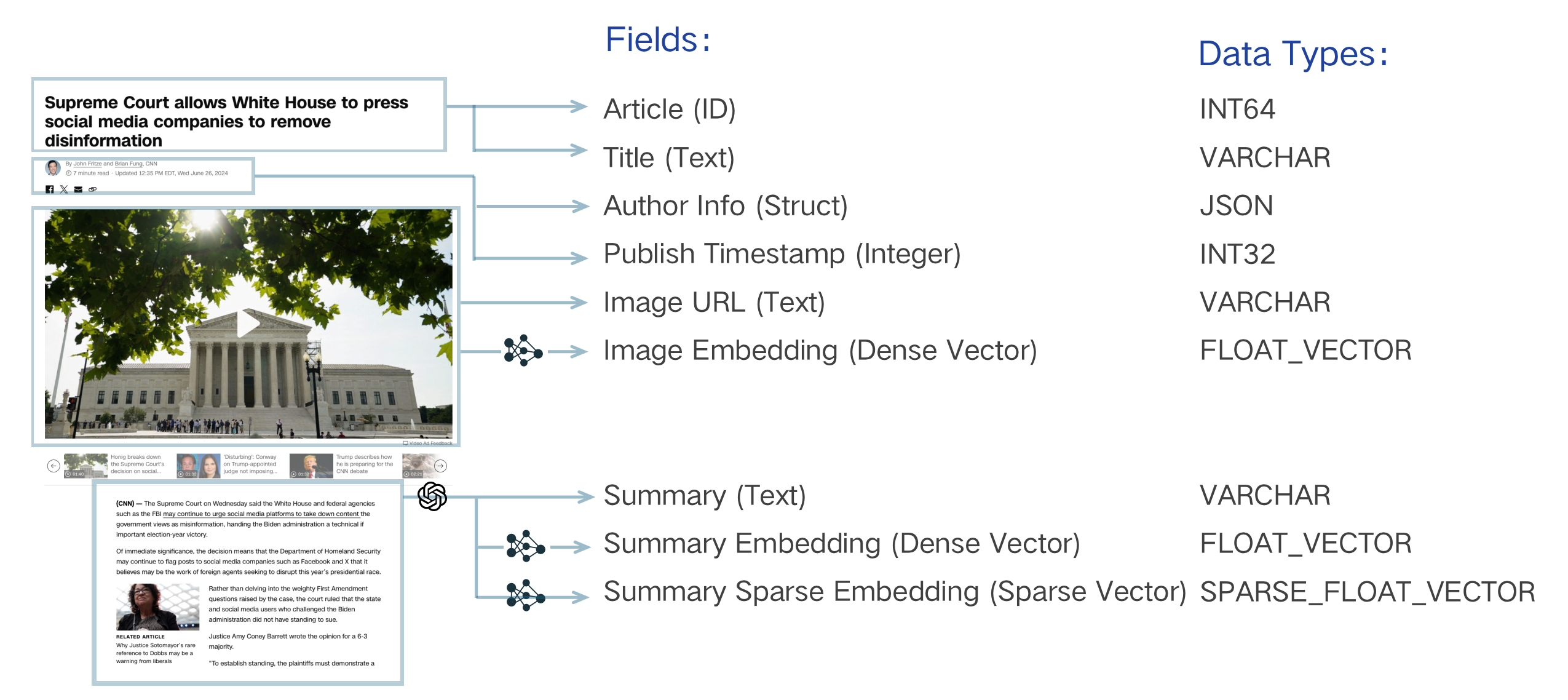
搜索系统的数据模型设计涉及分析业务需求并将信息抽象为 schema 表达的数据模型。例如,要搜索一段文本,必须通过"嵌入"将字面字符串转换为向量来"索引"它,从而启用向量搜索。除了这一基本要求外,可能还需要存储其他属性,如发布时间戳和作者。这些元数据允许通过过滤来细化语义搜索,仅返回在特定日期之后发布或由特定作者发布的文本。它们可能还需要与主文本一起检索,以便在应用程序中呈现搜索结果。要组织这些文本片段,每个都应该分配一个唯一标识符,表示为整数或字符串。这些元素对于实现复杂的搜索逻辑至关重要。
精心设计的 schema 很重要,因为它抽象了数据模型并决定是否可以通过搜索实现业务目标。此外,由于插入到 collection 中的每一行数据都需要遵循 schema,这极大地有助于维护数据一致性和长期质量。从技术角度来看,定义良好的 schema 会导致组织良好的列数据存储和更清洁的索引结构,这可以提高搜索性能。
示例:新闻搜索
假设我们想为新闻网站构建搜索功能,我们有包含文本、缩略图和其他元数据的新闻语料库。首先,我们需要分析如何利用数据来支持搜索的业务需求。想象一下,需求是根据缩略图和内容摘要检索新闻,并将作者信息和发布时间等元数据作为过滤搜索结果的标准。这些需求可以进一步分解为:
-
要通过文本搜索图像,我们可以通过多模态嵌入模型将图像嵌入到向量中,该模型可以将文本和图像数据映射到同一潜在空间。
-
文章的摘要文本通过文本嵌入模型嵌入到向量中。
-
要基于发布时间进行过滤,日期存储为标量字段,标量字段需要索引以实现高效过滤。其他更复杂的数据结构(如 JSON)可以存储在标量中,并对其内容执行过滤搜索(JSON 索引是即将推出的功能)。
-
要检索图像缩略图字节并在搜索结果页面上呈现它,图像 URL 也会被存储。同样,摘要文本和标题也是如此。(或者,如果需要,我们可以将原始文本和图像文件数据存储为标量字段。)
-
为了改进摘要文本的搜索结果,我们设计了混合搜索方法。对于一个检索路径,我们使用常规嵌入模型从文本生成密集向量,如 OpenAI 的
text-embedding-3-large或开源的bge-large-en-v1.5。这些模型擅长表示文本的整体语义。另一个路径是使用稀疏嵌入模型(如 BM25 或 SPLADE)生成稀疏向量,类似于擅长掌握文本中细节和个别概念的全文搜索。由于 Milvus 的多向量功能,Milvus 支持在同一数据 collection 中使用两者。对多个向量的搜索可以在单个hybrid_search()操作中完成。 -
最后,我们还需要一个 ID 字段来标识每个单独的新闻页面,在 Milvus 术语中正式称为"实体"。此字段用作主键(简称"pk")。
Field Name | article_id (Primary Key) | title | author_info | publish_ts | image_url | image_vector | summary | summary_dense_vector | summary_sparse_vector |
|---|---|---|---|---|---|---|---|---|---|
Type | INT64 | VARCHAR | JSON | INT32 | VARCHAR | FLOAT_VECTOR | VARCHAR | FLOAT_VECTOR | SPARSE_FLOAT_VECTOR |
Need Index | N | N | N (Support coming soon) | Y | N | Y | N | Y | Y |
如何实现示例 Schema
创建 Schema
首先,我们创建一个 Milvus 客户端实例,可用于连接到 Milvus 服务器并管理 collection 和数据。
要设置 schema,我们使用 create_schema() 创建 schema 对象,并使用 add_field() 向 schema 添加字段。
from pymilvus import MilvusClient, DataType
collection_name = "my_collection"
# client = MilvusClient(uri="http://localhost:19530")
client = MilvusClient(uri="./milvus_demo.db")
schema = MilvusClient.create_schema(
auto_id=False,
)
schema.add_field(field_name="article_id", datatype=DataType.INT64, is_primary=True, description="article id")
schema.add_field(field_name="title", datatype=DataType.VARCHAR, max_length=200, description="article title")
schema.add_field(field_name="author_info", datatype=DataType.JSON, description="author information")
schema.add_field(field_name="publish_ts", datatype=DataType.INT32, description="publish timestamp")
schema.add_field(field_name="image_url", datatype=DataType.VARCHAR, max_length=500, description="image URL")
schema.add_field(field_name="image_vector", datatype=DataType.FLOAT_VECTOR, dim=768, description="image vector")
schema.add_field(field_name="summary", datatype=DataType.VARCHAR, max_length=1000, description="article summary")
schema.add_field(field_name="summary_dense_vector", datatype=DataType.FLOAT_VECTOR, dim=768, description="summary dense vector")
schema.add_field(field_name="summary_sparse_vector", datatype=DataType.SPARSE_FLOAT_VECTOR, description="summary sparse vector")
import io.milvus.v2.common.DataType;
import io.milvus.v2.service.collection.request.AddFieldReq;
import io.milvus.v2.service.collection.request.CreateCollectionReq;
String collectionName = "my_collection";
CreateCollectionReq.CollectionSchema schema = client.createSchema();
schema.addField(AddFieldReq.builder()
.fieldName("article_id")
.dataType(DataType.Int64)
.isPrimaryKey(true)
.description("article id")
.build());
schema.addField(AddFieldReq.builder()
.fieldName("title")
.dataType(DataType.VarChar)
.maxLength(200)
.description("article title")
.build());
schema.addField(AddFieldReq.builder()
.fieldName("author_info")
.dataType(DataType.JSON)
.description("author information")
.build());
schema.addField(AddFieldReq.builder()
.fieldName("publish_ts")
.dataType(DataType.Int32)
.description("publish timestamp")
.build());
schema.addField(AddFieldReq.builder()
.fieldName("image_url")
.dataType(DataType.VarChar)
.maxLength(500)
.description("image URL")
.build());
schema.addField(AddFieldReq.builder()
.fieldName("image_vector")
.dataType(DataType.FloatVector)
.dimension(768)
.description("image vector")
.build());
schema.addField(AddFieldReq.builder()
.fieldName("summary")
.dataType(DataType.VarChar)
.maxLength(1000)
.description("article summary")
.build());
schema.addField(AddFieldReq.builder()
.fieldName("summary_dense_vector")
.dataType(DataType.FloatVector)
.dimension(768)
.description("summary dense vector")
.build());
schema.addField(AddFieldReq.builder()
.fieldName("summary_sparse_vector")
.dataType(DataType.SparseFloatVector)
.description("summary sparse vector")
.build());
const { MilvusClient } = require("@zilliz/milvus2-sdk-node");
const collectionName = "my_collection";
const client = new MilvusClient("http://localhost:19530");
const schema = [
{ name: "article_id", type: "INT64", is_primary: true, description: "article id" },
{ name: "title", type: "VARCHAR", max_length: 200, description: "article title" },
{ name: "author_info", type: "JSON", description: "author information" },
{ name: "publish_ts", type: "INT32", description: "publish timestamp" },
{ name: "image_url", type: "VARCHAR", max_length: 500, description: "image URL" },
{ name: "image_vector", type: "FLOAT_VECTOR", dim: 768, description: "image vector" },
{ name: "summary", type: "VARCHAR", max_length: 1000, description: "article summary" },
{ name: "summary_dense_vector", type: "FLOAT_VECTOR", dim: 768, description: "summary dense vector" },
{ name: "summary_sparse_vector", type: "SPARSE_FLOAT_VECTOR", description: "summary sparse vector" },
];
import (
"context"
"fmt"
"github.com/milvus-io/milvus/client/v2/entity"
"github.com/milvus-io/milvus/client/v2/index"
"github.com/milvus-io/milvus/client/v2/milvusclient"
)
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
milvusAddr := "localhost:19530"
client, err := milvusclient.New(ctx, &milvusclient.ClientConfig{
Address: milvusAddr,
})
if err != nil {
fmt.Println(err.Error())
// handle error
}
defer client.Close(ctx)
collectionName := "my_collection"
schema := entity.NewSchema()
schema.WithField(entity.NewField().
WithName("article_id").
WithDataType(entity.FieldTypeInt64).
WithIsPrimaryKey(true).
WithDescription("article id"),
).WithField(entity.NewField().
WithName("title").
WithDataType(entity.FieldTypeVarChar).
WithMaxLength(200).
WithDescription("article title"),
).WithField(entity.NewField().
WithName("author_info").
WithDataType(entity.FieldTypeJSON).
WithDescription("author information"),
).WithField(entity.NewField().
WithName("publish_ts").
WithDataType(entity.FieldTypeInt32).
WithDescription("publish timestamp"),
).WithField(entity.NewField().
WithName("image_url").
WithDataType(entity.FieldTypeVarChar).
WithMaxLength(500).
WithDescription("image url"),
).WithField(entity.NewField().
WithName("image_vector").
WithDataType(entity.FieldTypeFloatVector).
WithDim(768).
WithDescription("image vector"),
).WithField(entity.NewField().
WithName("summary").
WithDataType(entity.FieldTypeVarChar).
WithMaxLength(1000).
WithDescription("article summary"),
).WithField(entity.NewField().
WithName("summary_dense_vector").
WithDataType(entity.FieldTypeFloatVector).
WithDim(768).
WithDescription("summary dense vector"),
).WithField(entity.NewField().
WithName("summary_sparse_vector").
WithDataType(entity.FieldTypeSparseVector).
WithDescription("summary sparse vector"),
)
# restful
export idField='{
"fieldName": "article_id",
"dataType": "Int64",
"isPrimary": true
}'
export titleField='{
"fieldName": "title",
"dataType": "VarChar",
"elementTypeParams": {
"max_length": 200
}
}'
export authorField='{
"fieldName": "author_info",
"dataType": "JSON"
}'
export publishField='{
"fieldName": "publish_ts",
"dataType": "Int32"
}'
export imgField='{
"fieldName": "image_url",
"dataType": "VarChar",
"elementTypeParams": {
"max_length": 500
}
}'
export imgVecField='{
"fieldName": "image_vector",
"dataType": "FloatVector",
"elementTypeParams": {
"dim": 5
}
}'
export summaryField='{
"fieldName": "summary",
"dataType": "VarChar",
"elementTypeParams": {
"max_length": 1000
}
}'
export summaryDenseField='{
"fieldName": "summary_dense_vector",
"dataType": "FloatVector",
"elementTypeParams": {
"dim": 768
}
}'
export summarySparseField='{
"fieldName": "summary_sparse_vector",
"dataType": "SparseFloatVector",
"elementTypeParams": {
"dim": 768
}
}'
export schema="{
\"autoID\": false,
\"fields\": [
$idField,
$titleField,
$authorField,
$publishField,
$imgField,
$imgVecField,
$summaryField,
$summaryDenseField,
$summarySparseField
]
}"
您可能注意到 MilvusClient 中的参数 uri,用于连接到 Milvus 服务器。您可以设置如下参数:
-
如果您只需要一个用于小规模数据或原型设计的本地向量数据库,将 uri 设置为本地文件,例如
./milvus.db,是最便捷的方法,因为它会自动利用 Milvus Lite 将所有数据存储在此文件中。 -
如果您有大规模数据,比如超过一百万个向量,您可以在 Docker 或 Kubernetes 上设置性能更高的 Milvus 服务器。在这种设置中,请使用服务器地址和端口作为您的 uri,例如
http://localhost:19530。如果您在 Milvus 上启用了身份验证功能,请使用 "<your_username>:<your_password>" 作为 token,否则不要设置 token。 -
如果您使用 Zilliz Cloud,即 Milvus 的完全托管云服务,请调整
uri和token,它们对应于 Zilliz Cloud 中的公共端点和 API 密钥。
至于 MilvusClient.create_schema 中的 auto_id,AutoID 是 primary field 的一个属性,确定是否为 primary field 启用自动递增。由于我们将字段 article_id 设置为主键并希望手动添加文章 ID,因此我们将 auto_id 设置为 False 以禁用此功能。
将所有字段添加到 schema 对象后,我们的 schema 对象与上表中的条目一致。
定义 Index
在定义了包含元数据和图像及摘要数据向量字段的 schema 后,下一步涉及准备索引参数。索引对于优化向量的搜索和检索至关重要,确保高效的查询性能。在下面的部分中,我们将为 collection 中指定的向量和标量字段定义索引参数。
index_params = client.prepare_index_params()
index_params.add_index(
field_name="image_vector",
index_type="AUTOINDEX",
metric_type="IP",
)
index_params.add_index(
field_name="summary_dense_vector",
index_type="AUTOINDEX",
metric_type="IP",
)
index_params.add_index(
field_name="summary_sparse_vector",
index_type="SPARSE_INVERTED_INDEX",
metric_type="IP",
)
index_params.add_index(
field_name="publish_ts",
index_type="INVERTED",
)
import io.milvus.v2.common.IndexParam;
import java.util.ArrayList;
import java.util.List;
List<IndexParam> indexes = new ArrayList<>();
indexes.add(IndexParam.builder()
.fieldName("image_vector")
.indexType(IndexParam.IndexType.AUTOINDEX)
.metricType(IndexParam.MetricType.IP)
.build());
indexes.add(IndexParam.builder()
.fieldName("summary_dense_vector")
.indexType(IndexParam.IndexType.AUTOINDEX)
.metricType(IndexParam.MetricType.IP)
.build());
indexes.add(IndexParam.builder()
.fieldName("summary_sparse_vector")
.indexType(IndexParam.IndexType.SPARSE_INVERTED_INDEX)
.metricType(IndexParam.MetricType.IP)
.build());
indexes.add(IndexParam.builder()
.fieldName("publish_ts")
.indexType(IndexParam.IndexType.INVERTED)
.build());
const { IndexType, MetricType } = require("@zilliz/milvus2-sdk-node");
const index_params = [
{
field_name: "image_vector",
index_type: IndexType.AUTOINDEX,
metric_type: MetricType.IP,
},
{
field_name: "summary_dense_vector",
index_type: IndexType.AUTOINDEX,
metric_type: MetricType.IP,
},
{
field_name: "summary_sparse_vector",
index_type: IndexType.SPARSE_INVERTED_INDEX,
metric_type: MetricType.IP,
},
{
field_name: "publish_ts",
index_type: IndexType.INVERTED,
},
];
indexOption1 := milvusclient.NewCreateIndexOption(collectionName, "image_vector",
index.NewAutoIndex(index.MetricType(entity.IP)))
indexOption2 := milvusclient.NewCreateIndexOption(collectionName, "summary_dense_vector",
index.NewAutoIndex(index.MetricType(entity.IP)))
indexOption3 := milvusclient.NewCreateIndexOption(collectionName, "summary_sparse_vector",
index.NewSparseInvertedIndex(index.MetricType(entity.IP), 0.2))
indexOption4 := milvusclient.NewCreateIndexOption(collectionName, "publish_ts",
index.NewInvertedIndex())
# restful
indexParams='[
{
"fieldName": "image_vector",
"params": {
"index_type": "AUTOINDEX",
"metric_type": "IP"
}
},
{
"fieldName": "summary_dense_vector",
"params": {
"index_type": "AUTOINDEX",
"metric_type": "IP"
}
},
{
"fieldName": "summary_sparse_vector",
"params": {
"index_type": "AUTOINDEX",
"metric_type": "IP"
}
},
{
"fieldName": "publish_ts",
"params": {
"index_type": "AUTOINDEX"
}
}
]'
一旦索引参数设置并应用,Milvus 就会针对处理向量和标量数据的复杂查询进行优化。这种索引增强了 collection 内相似性搜索的性能和准确性,允许基于图像向量和摘要向量高效检索文章。通过对密集向量利用 AUTOINDEX,对稀疏向量利用 SPARSE_INVERTED_INDEX,对标量利用 INVERTED_INDEX,Milvus 可以快速识别并返回最相关的结果,显著改善数据检索过程的整体用户体验和效果。
有许多类型的索引和度量。有关更多信息,您可以参阅 Milvus 索引类型 和 Milvus 度量类型。
创建 Collection
定义了 schema 和索引后,我们使用这些参数创建一个"collection"。Collection 对于 Milvus 就像表对于关系数据库一样。
client.create_collection(
collection_name=collection_name,
schema=schema,
index_params=index_params,
)
CreateCollectionReq requestCreate = CreateCollectionReq.builder()
.collectionName(collectionName)
.collectionSchema(schema)
.indexParams(indexes)
.build();
client.createCollection(requestCreate);
const client.create_collection({
collection_name: collection_name,
schema: schema,
index_params: index_params,
});
err = client.CreateCollection(ctx,
milvusclient.NewCreateCollectionOption(collectionName, schema).
WithIndexOptions(indexOption1, indexOption2, indexOption3, indexOption4))
if err != nil {
fmt.Println(err.Error())
// handle error
}
# restful
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/collections/create" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
--data "{
\"collectionName\": \"my_collection\",
\"schema\": $schema,
\"indexParams\": $indexParams
}"
我们可以通过描述 collection 来验证 collection 是否已成功创建。
collection_desc = client.describe_collection(
collection_name=collection_name
)
print(collection_desc)
DescribeCollectionResp descResp = client.describeCollection(DescribeCollectionReq.builder()
.collectionName(collectionName)
.build());
System.out.println(descResp);
const collection_desc = await client.describeCollection({
collection_name: collection_name
});
console.log(collection_desc);
desc, err := client.DescribeCollection(ctx, milvusclient.NewDescribeCollectionOption(collectionName))
if err != nil {
fmt.Println(err.Error())
// handle error
}
fmt.Println(desc.Schema)
# restful
curl --request POST \
--url "http://localhost:19530/v2/vectordb/collections/describe" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
-d '{
"collectionName": $collection_name
}'
其他考虑因素
加载 Index
在 Milvus 中创建 collection 时,您可以选择立即加载索引或推迟到批量摄取一些数据之后。通常,您不需要对此做出明确选择,因为上面的示例显示,在创建 collection 后,索引会为任何摄取的数据自动构建。这允许立即搜索摄取的数据。但是,如果您在创建 collection 后有大量批量插入,并且在某个时间点之前不需要搜索任何数据,您可以通过在创建 collection 时省略 index_params 来推迟索引构建,并在摄取所有数据后通过显式调用 load 来构建索引。这种方法对于在大型 collection 上构建索引更高效,但在调用 load() 之前无法进行搜索。
如何为多租户定义数据模型
多租户的概念通常用于单个软件应用程序或服务需要为多个独立用户或组织提供服务的场景,每个用户或组织都有自己的隔离环境。这在云计算、SaaS(软件即服务)应用程序和数据库系统中很常见。例如,云存储服务可能利用多租户来允许不同公司在共享相同底层基础架构的同时分别存储和管理其数据。这种方法最大化了资源利用率和效率,同时确保每个租户的数据安全和隐私。
区分租户的最简单方法是将其数据和资源彼此隔离。每个租户要么对特定资源具有独占访问权,要么与其他租户共享资源以管理 Milvus 实体,如数据库、collection 和 partition。有与这些实体一致的特定方法来实现多租户。您可以参阅 Milvus 多租户页面 了解更多信息。