概述
Milvus-CDC 是一个用户友好的工具,可以捕获和同步 Milvus 实例中的增量数据。它通过在源实例和目标实例之间无缝传输业务数据来确保业务数据的可靠性,从而轻松实现增量备份和灾难恢复。
关键功能
-
顺序数据同步:通过在 Milvus 实例之间按顺序同步数据变更来确保数据完整性和一致性。
-
增量数据复制:从源 Milvus 复制增量数据,包括插入和删除,到目标 Milvus,提供持久存储。
-
CDC 任务管理:允许通过 OpenAPI 请求管理 CDC 任务,包括创建、查询状态和删除 CDC 任务。
此外,我们计划在未来扩展我们的功能,包括支持与流处理系统的集成。
架构
Milvus-CDC 采用包含两个主要组件的架构 - 一个管理任务和元数据的 HTTP server,以及 corelib,它同步任务执行,其中 reader 从源 Milvus 实例获取数据,writer 将处理后的数据发送到目标 Milvus 实例。
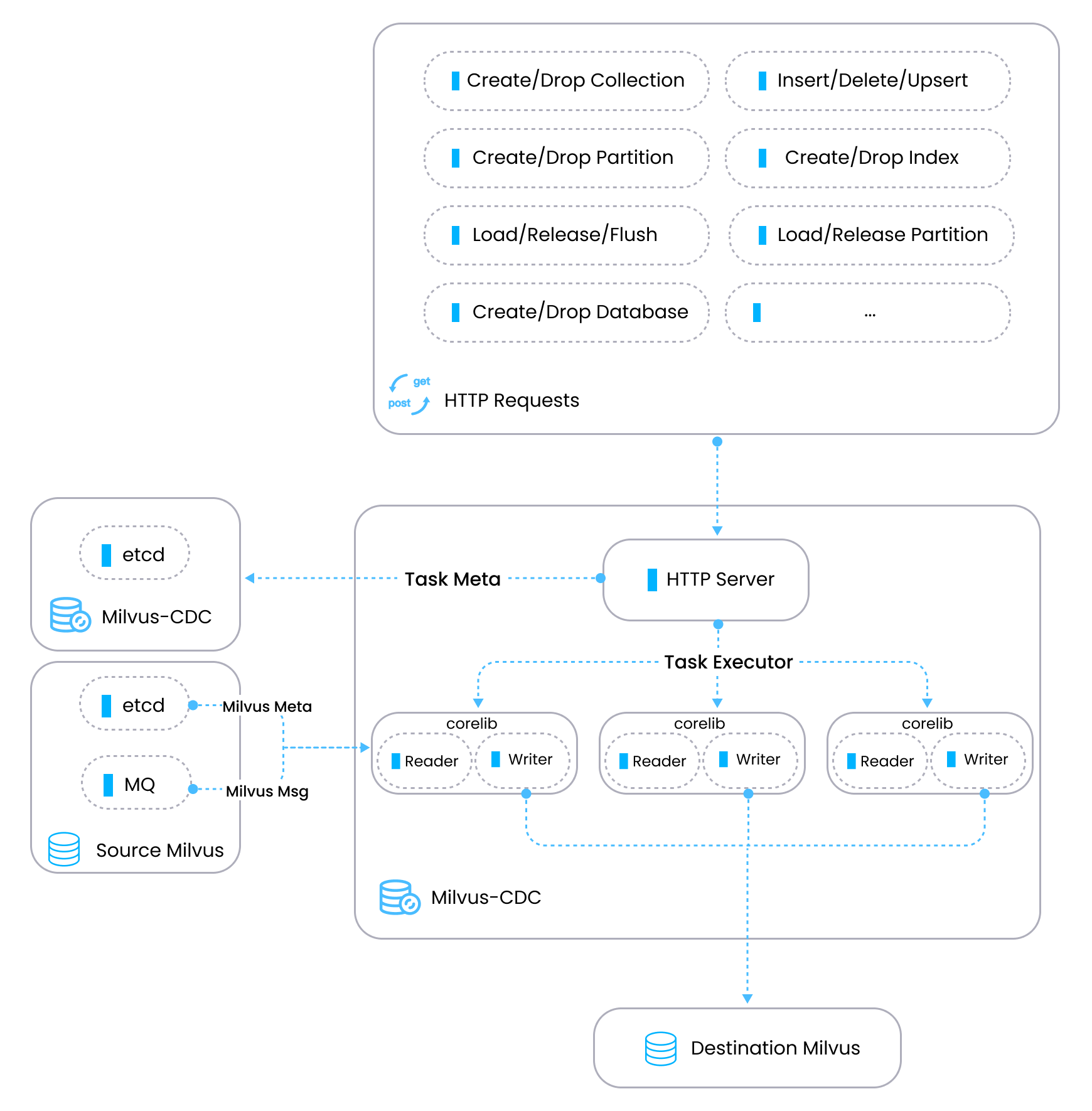
在上图中,
-
HTTP server:处理用户请求、执行任务并维护元数据。它作为 Milvus-CDC 系统内任务编排的控制平面。
-
Corelib:负责任务的实际同步。它包括一个 reader 组件,从源 Milvus 的 etcd 和消息队列(MQ)检索信息,以及一个 writer 组件,将 MQ 中的消息转换为 Milvus 系统的 API 参数,并将这些请求发送到目标 Milvus 以完成同步过程。
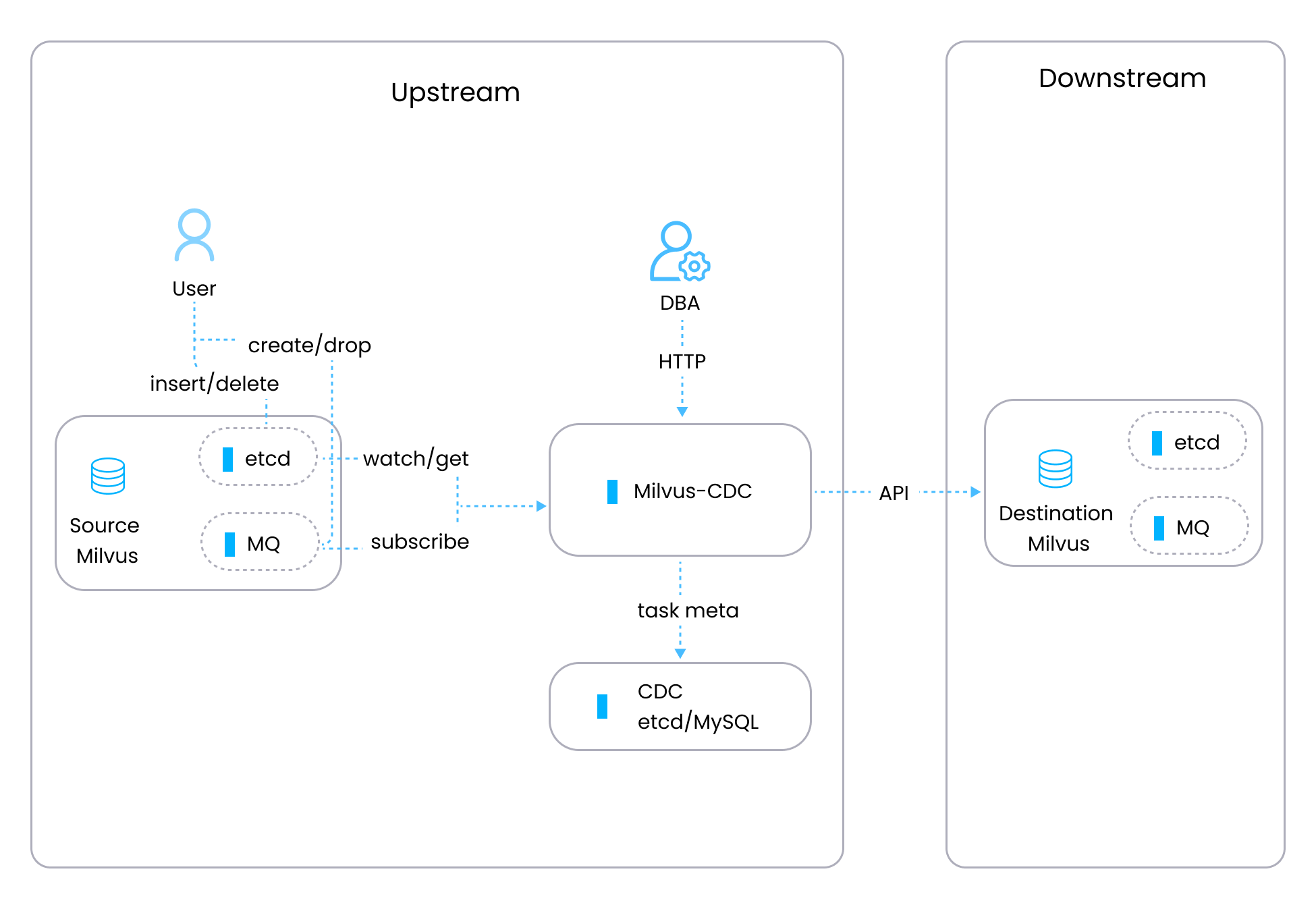
工作流程
Milvus-CDC 数据处理流程包括以下步骤:
-
任务创建:用户通过 HTTP 请求启动 CDC 任务。
-
元数据检索:系统从源 Milvus 的 etcd 获取 collection 特定的元数据,包括 collection 的通道和检查点信息。
-
MQ 连接:有了元数据后,系统连接到 MQ 开始订阅数据流。
-
数据处理:从 MQ 读取数据,解析并使用 Go SDK 传递,或处理以复制在源 Milvus 中执行的操作。
限制
-
增量数据同步:目前,Milvus-CDC 设计为仅同步增量数据。如果您的业务需要完整数据备份,请联系我们寻求帮助。
-
同步范围:目前,Milvus-CDC 可以在集群级别同步数据。我们正在努力在即将发布的版本中添加对 collection 级别数据同步的支持。
-
支持的 API 请求:Milvus-CDC 目前支持以下 API 请求。我们计划在未来版本中扩展对更多请求的支持:
-
Create/Drop Collection
-
Insert/Delete/Upsert
-
Create/Drop Partition
-
Create/Drop Index
-
Load/Release/Flush
-
Load/Release Partition
-
Create/Drop Database
-