HNSW
HNSW index 是一种基于图的索引算法,可以在搜索高维浮点向量时提高性能。它提供出色的搜索准确性和低延迟,同时需要高内存开销来维护其分层图结构。
概述
分层可导航小世界 (HNSW) 算法构建一个多层图,有点像具有不同缩放级别的地图。底层包含所有数据点,而上层由从下层采样的数据点子集组成。
在这个层次结构中,每一层都包含表示数据点的节点,通过表示其邻近性的边连接。更高的层提供长距离跳跃以快速接近目标,而较低的层启用细粒度搜索以获得最准确的结果。
工作原理如下:
-
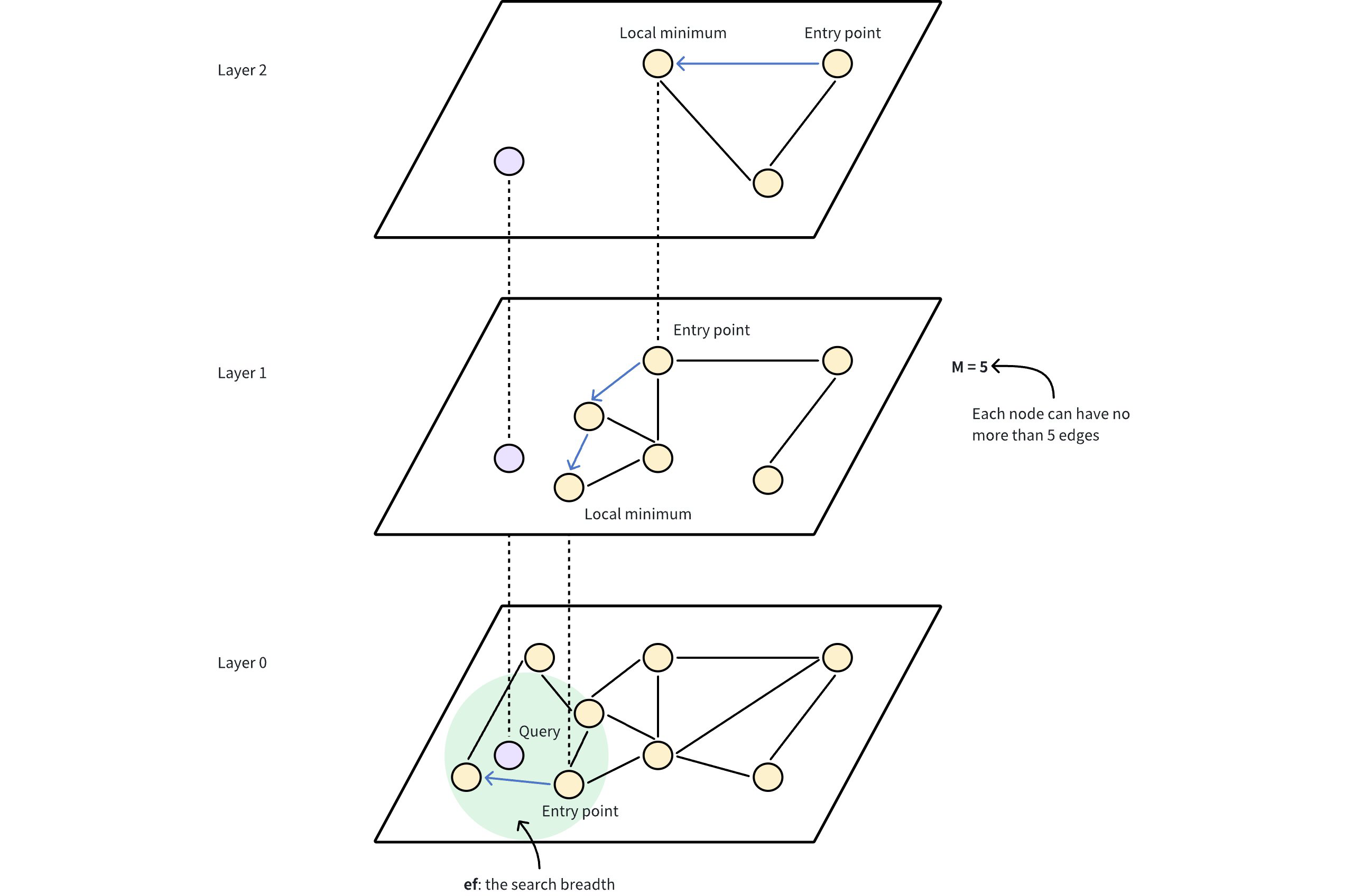
入口点:搜索从顶层的固定入口点开始,这是图中的预定节点。
-
贪婪搜索:算法贪婪地移动到当前层的最近邻居,直到它无法更接近查询向量。上层具有导航目的,充当粗过滤器来定位较低级别精细搜索的潜在入口点。
-
层下降:一旦在当前层达到局部最小值,算法使用预先建立的连接跳转到下层,并重复贪婪搜索。
-
最终细化:此过程持续到达到底层,在那里最终细化步骤识别最近邻居。
HNSW 的性能取决于几个关键参数,这些参数控制图的结构和搜索行为。包括:
-
M:层次结构每一级图中每个节点可以拥有的最大边数或连接数。更高的M会导致更密集的图,并增加召回率和准确性,因为搜索有更多路径可探索,这也会消耗更多内存并由于额外连接而减慢插入时间。如上图所示,M = 5 表示 HNSW 图中的每个节点直接连接到最多 5 个其他节点。这创建了一个适度密集的图结构,其中节点有多个路径到达其他节点。 -
efConstruction:索引构建期间考虑的候选数量。更高的efConstruction通常会产生更好质量的图,但需要更多时间来构建。 -
ef:搜索期间评估的邻居数量。增加ef提高找到最近邻居的可能性,但会减慢搜索过程。
有关如何调整这些设置以满足您需求的详细信息,请参阅 Index 参数。
构建 Index
要在 Milvus 中的向量 field 上构建 HNSW index,使用 add_index() 方法,指定 index_type、metric_type 和 index 的其他参数。
from pymilvus import MilvusClient
# Prepare index building params
index_params = MilvusClient.prepare_index_params()
index_params.add_index(
field_name="your_vector_field_name", # Name of the vector field to be indexed
index_type="HNSW", # Type of the index to create
index_name="vector_index", # Name of the index to create
metric_type="L2", # Metric type used to measure similarity
params={
"M": 64, # Maximum number of neighbors each node can connect to in the graph
"efConstruction": 100 # Number of candidate neighbors considered for connection during index construction
} # Index building params
)
在此配置中:
-
index_type:要构建的 index 类型。在此示例中,将值设置为HNSW。 -
metric_type:用于计算向量之间距离的方法。支持的值包括COSINE、L2和IP。有关详细信息,请参阅 度量类型。 -
params:构建 index 的其他配置选项。-
M:每个节点可以连接的最大邻居数。 -
efConstruction:索引构建期间考虑连接的候选邻居数量。
要了解
HNSWindex 可用的更多构建参数,请参阅 Index 构建参数。 -
配置 index 参数后,您可以直接使用 create_index() 方法创建 index,或在 create_collection 方法中传递 index 参数。有关详细信息,请参阅 创建 Collection。
在 Index 上搜索
构建 index 并插入 entity 后,您可以在 index 上执行相似性搜索。
search_params = {
"params": {
"ef": 10, # Number of neighbors to consider during the search
}
}
res = MilvusClient.search(
collection_name="your_collection_name", # Collection name
anns_field="vector_field", # Vector field name
data=[[0.1, 0.2, 0.3, 0.4, 0.5]], # Query vector
limit=10, # TopK results to return
search_params=search_params
)
在此配置中:
-
params:在 index 上搜索的其他配置选项。ef:搜索期间考虑的邻居数量。
要了解
HNSWindex 可用的更多搜索参数,请参阅 Index 特定搜索参数。
Index 参数
本节概述了用于构建 index 和在 index 上执行搜索的参数。
Index 构建参数
下表列出了在构建 index 时可以在 params 中配置的参数。
参数 | 描述 | 值范围 | 调优建议 |
|---|---|---|---|
| 图中每个节点可以拥有的最大连接数(或边),包括传出和传入边。此参数直接影响索引构建和搜索。 | 类型:整数 范围:[2, 2048] 默认值: | 更大的 当内存使用和搜索速度是主要关注点时,考虑减少 在大多数情况下,我们建议您在此范围内设置值:[5, 100]。 |
| 索引构建期间考虑连接的候选邻居数量。为每个新元素评估更大的候选池,但实际建立的最大连接数仍受 | 类型:整数 范围:[1, int_max] 默认值: | 更高的 当资源约束是关注点时,考虑减少 在大多数情况下,我们建议您在此范围内设置值:[50, 500]。 |
Index 特定搜索参数
下表列出了在在 index 上搜索时可以在 search_params.params 中配置的参数。
参数 | 描述 | 值范围 | 调优建议 |
|---|---|---|---|
| 控制最近邻检索期间搜索的广度。它确定访问和评估多少节点作为潜在最近邻居。此参数仅影响搜索过程,并专门应用于图的底层。 | 类型:整数 范围:[1, int_max] 默认值:limit(要返回的 TopK 最近邻居) | 更大的 考虑减少 在大多数情况下,我们建议您在此范围内设置值:[K, 10K]。 |