重排序
混合搜索通过多个同时进行的 ANN 搜索实现更精确的搜索结果。多个搜索返回多组结果,需要重排序策略来帮助合并和重新排序结果并返回单一结果集。本指南将介绍 Milvus 支持的重排序策略,并提供选择适当重排序策略的技巧。
概述
下图显示了在多模态搜索应用程序中进行混合搜索的主要工作流程。在图中,一条路径是对文本的基本 ANN 搜索,另一条路径是对图像的基本 ANN 搜索。每条路径分别基于文本和图像相似性分数生成一组结果(Limit 1 和 Limit 2)。然后应用重排序策略基于统一标准对两组结果进行重排序,最终将两组结果合并为最终的搜索结果集,Limit(final)。
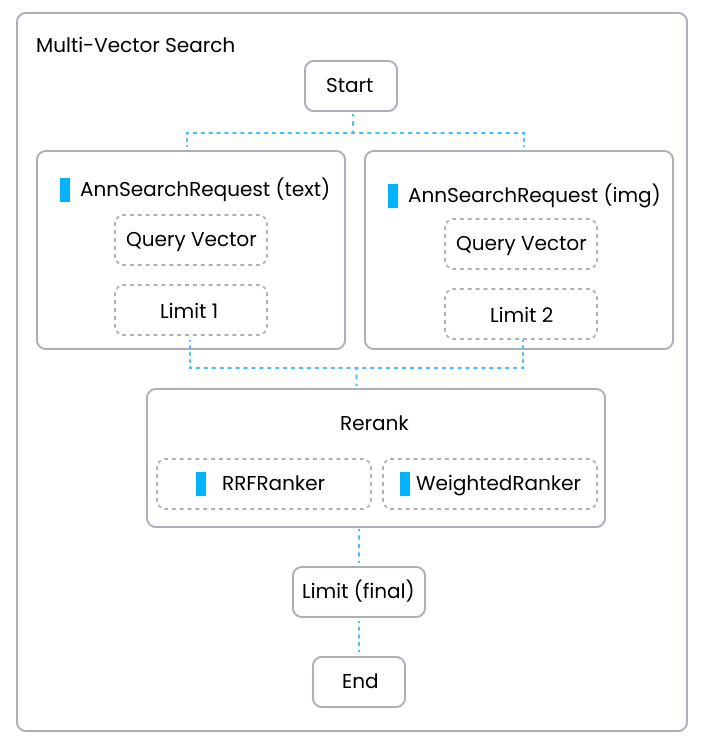
在混合搜索中,重排序是一个关键步骤,它整合来自多个向量搜索的结果,以确保最终输出是最相关和准确的。目前,Milvus 支持以下两种重排序策略:
-
WeightedRanker:此策略通过计算来自不同向量搜索的分数(或距离)的加权分数来合并结果。权重根据每个向量 field 的重要性分配,允许根据特定用例优先级进行自定义。
-
RRFRanker(倒数排名融合排序器):此策略基于排名组合结果。它使用一种平衡来自不同搜索的结果排名的方法,通常导致更公平和有效的不同数据类型或模态的整合。
WeightedRanker
WeightedRanker 策略根据每条向量搜索路径的重要性为其结果分配不同的权重。
WeightedRanker 的机制
WeightedRanker 策略的主要工作流程如下:
-
收集搜索分数:收集每条向量搜索路径的结果和分数(score_1、score_2)。
-
分数归一化:每次搜索可能使用不同的相似性度量,导致分数分布不同。例如,使用内积(IP)作为相似性类型可能导致分数范围为 [−∞,+∞],而使用欧几里得距离(L2)导致分数范围为 [0,+∞]。由于不同搜索的分数范围不同且无法直接比较,因此需要对每条搜索路径的分数进行归一化。通常,应用
arctan函数将分数转换为 [0, 1] 范围内(score_1_normalized、score_2_normalized)。接近 1 的分数表示更高的相似性。 -
分配权重:根据分配给不同向量 field 的重要性,将权重(wi)分配给归一化分数(score_1_normalized、score_2_normalized)。每条路径的权重应在 [0,1] 范围内。结果加权分数为 score_1_weighted 和 score_2_weighted。
-
合并分数:加权分数(score_1_weighted、score_2_weighted)从高到低排序以产生最终分数集(score_final)。

WeightedRanker 示例
此示例演示了涉及图像和文本的多模态混合搜索(topK=5),并说明了 WeightedRanker 策略如何对来自两个 ANN 搜索的结果进行重排序。
- 图像 ANN 搜索结果(topK=5):
ID | 分数(图像) |
|---|---|
101 | 0.92 |
203 | 0.88 |
150 | 0.85 |
198 | 0.83 |
175 | 0.8 |
- 文本 ANN 搜索结果(topK=5):
ID | 分数(文本) |
|---|---|
198 | 0.91 |
101 | 0.87 |
110 | 0.85 |
175 | 0.82 |
250 | 0.78 |
- 使用 WeightedRanker 为图像和文本搜索结果分配权重。假设图像 ANN 搜索的权重为 0.6,文本搜索的权重为 0.4。
ID | 分数(图像) | 分数(文本) | 加权分数 |
|---|---|---|---|
101 | 0.92 | 0.87 | 0.6×0.92+0.4×0.87=0.90 |
203 | 0.88 | N/A | 0.6×0.88+0.4×0=0.528 |
150 | 0.85 | N/A | 0.6×0.85+0.4×0=0.51 |
198 | 0.83 | 0.91 | 0.6×0.83+0.4×0.91=0.86 |
175 | 0.80 | 0.82 | 0.6×0.80+0.4×0.82=0.81 |
110 | 不在图像中 | 0.85 | 0.6×0+0.4×0.85=0.34 |
250 | 不在图像中 | 0.78 | 0.6×0+0.4×0.78=0.312 |
- 重排序后的最终结果(topK=5):
排名 | ID | 最终分数 |
|---|---|---|
1 | 101 | 0.90 |
2 | 198 | 0.86 |
3 | 175 | 0.81 |
4 | 203 | 0.528 |
5 | 150 | 0.51 |
WeightedRanker 的使用
使用 WeightedRanker 策略时,需要输入权重值。输入的权重值数量应与混合搜索中基本 ANN 搜索请求的数量相对应。输入的权重值应在 [0,1] 范围内,接近 1 的值表示更大的重要性。
例如,假设混合搜索中有两个基本 ANN 搜索请求:文本搜索和图像搜索。如果文本搜索被认为更重要,应该分配更大的权重。
from pymilvus import WeightedRanker
rerank= WeightedRanker(0.8, 0.3)
import io.milvus.v2.service.vector.request.ranker.WeightedRanker;
WeightedRanker rerank = new WeightedRanker(Arrays.asList(0.8f, 0.3f))
import "github.com/milvus-io/milvus/client/v2/milvusclient"
reranker := milvusclient.NewWeightedReranker([]float64{0.8, 0.3})
rerank: WeightedRanker(0.8, 0.3)
export rerank='{
"strategy": "ws",
"params": {"weights": [0.8,0.3]}
}'
RRFRanker
倒数排名融合(RRF)是一种数据融合方法,它基于排名的倒数来组合排名列表。这种重排序策略有效地平衡了每个向量搜索路径的重要性。
RRFRanker 的机制
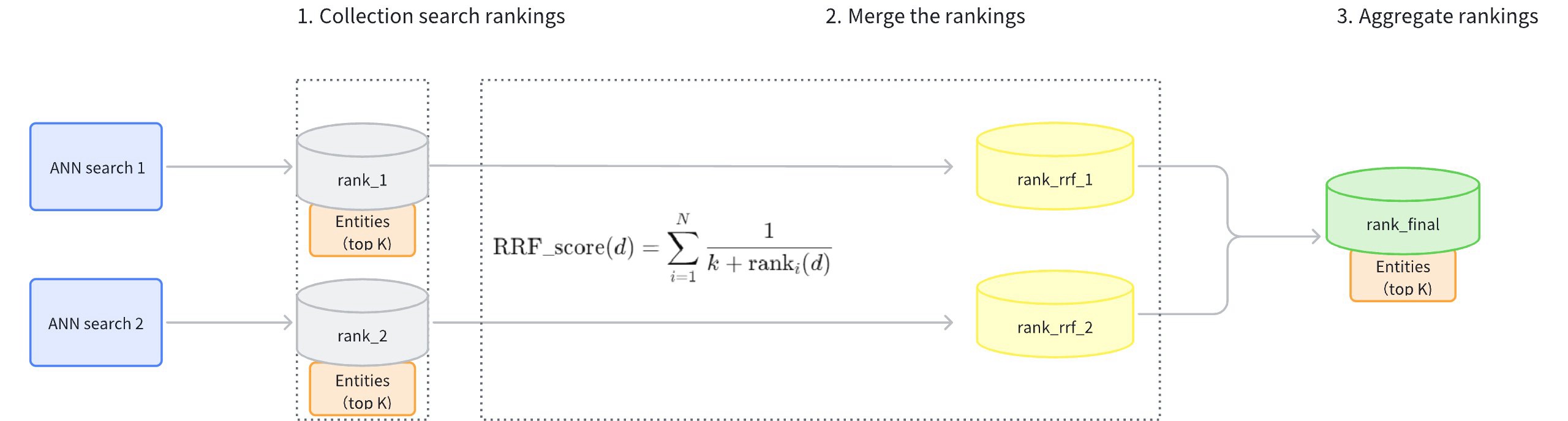
RRFRanker 策略的主要工作流程如下:
-
收集搜索排名:收集每条向量搜索路径结果的排名(rank_1、rank_2)。
-
合并排名:根据公式将每条路径的排名(rank_rrf_1、rank_rrf_2)进行转换。
计算公式涉及 N,它表示检索的数量。ranki(d) 是由第 i 个检索器生成的文档 d 的排名位置。k 是一个平滑参数,通常设置为 60。
-
聚合排名:基于合并的排名对搜索结果进行重新排序以产生最终结果。
RRFRanker 示例
此示例演示了稀疏-密集向量的混合搜索(topK=5),并说明了 RRFRanker 策略如何对来自两个 ANN 搜索的结果进行重排序。
- 文本稀疏向量 ANN 搜索结果(topK=5):
ID | 排名(稀疏) |
|---|---|
101 | 1 |
203 | 2 |
150 | 3 |
198 | 4 |
175 | 5 |
- 文本密集向量 ANN 搜索结果(topK=5):
ID | 排名(密集) |
|---|---|
198 | 1 |
101 | 2 |
110 | 3 |
175 | 4 |
250 | 5 |
- 使用 RRF 重新安排两组搜索结果的排名。假设平滑参数
k设置为 60。
ID | 分数(稀疏) | 分数(密集) | 最终分数 |
|---|---|---|---|
101 | 1 | 2 | 1/(60+1)+1/(60+2) = 0.01639 |
198 | 4 | 1 | 1/(60+4)+1/(60+1) = 0.01593 |
175 | 5 | 4 | 1/(60+5)+1/(60+4) = 0.01554 |
203 | 2 | N/A | 1/(60+2) = 0.01613 |
150 | 3 | N/A | 1/(60+3) = 0.01587 |
110 | N/A | 3 | 1/(60+3) = 0.01587 |
250 | N/A | 5 | 1/(60+5) = 0.01554 |
- 重排序后的最终结果(topK=5):
排名 | ID | 最终分数 |
|---|---|---|
1 | 101 | 0.01639 |
2 | 203 | 0.01613 |
3 | 198 | 0.01593 |
4 | 150 | 0.01587 |
5 | 110 | 0.01587 |
RRFRanker 的使用
使用 RRF 重排序策略时,您需要配置参数 k。它是一个平滑参数,可以有效改变全文搜索与向量搜索的相对权重。此参数的默认值为 60,可以在 (0, 16384) 范围内调整。该值应为浮点数。推荐值在 [10, 100] 之间。虽然 k=60 是常见选择,但最佳的 k 值可以因您的具体应用和数据集而异。我们建议根据您的具体用例测试和调整此参数,以获得最佳性能。
选择合适的重排序策略
在选择重排序策略时,需要考虑的一点是是否要对向量 field 上的一个或多个基本 ANN 搜索有任何强调。
-
WeightedRanker:如果您需要结果强调特定向量 field,建议使用此策略。WeightedRanker 允许您为某些向量 field 分配更高的权重,从而更多地强调它们。例如,在多模态搜索中,图像的文本描述可能被认为比该图像中的颜色更重要。
-
RRFRanker(倒数排名融合排名器):当没有特定强调时,建议使用此策略。RRF 可以有效地平衡每个向量 field 的重要性。