聚类压缩
聚类压缩旨在改善大型 collection 中的搜索性能并降低成本。本指南将帮助您了解聚类压缩以及此功能如何改善搜索性能。
概述
Milvus 将传入的实体存储在 collection 内的 segment 中,并在 segment 满时将其封存。如果发生这种情况,将创建一个新的 segment 来容纳额外的实体。因此,实体在 segment 之间任意分布。这种分布要求 Milvus 搜索多个 segment 以找到给定查询向量的最近邻。
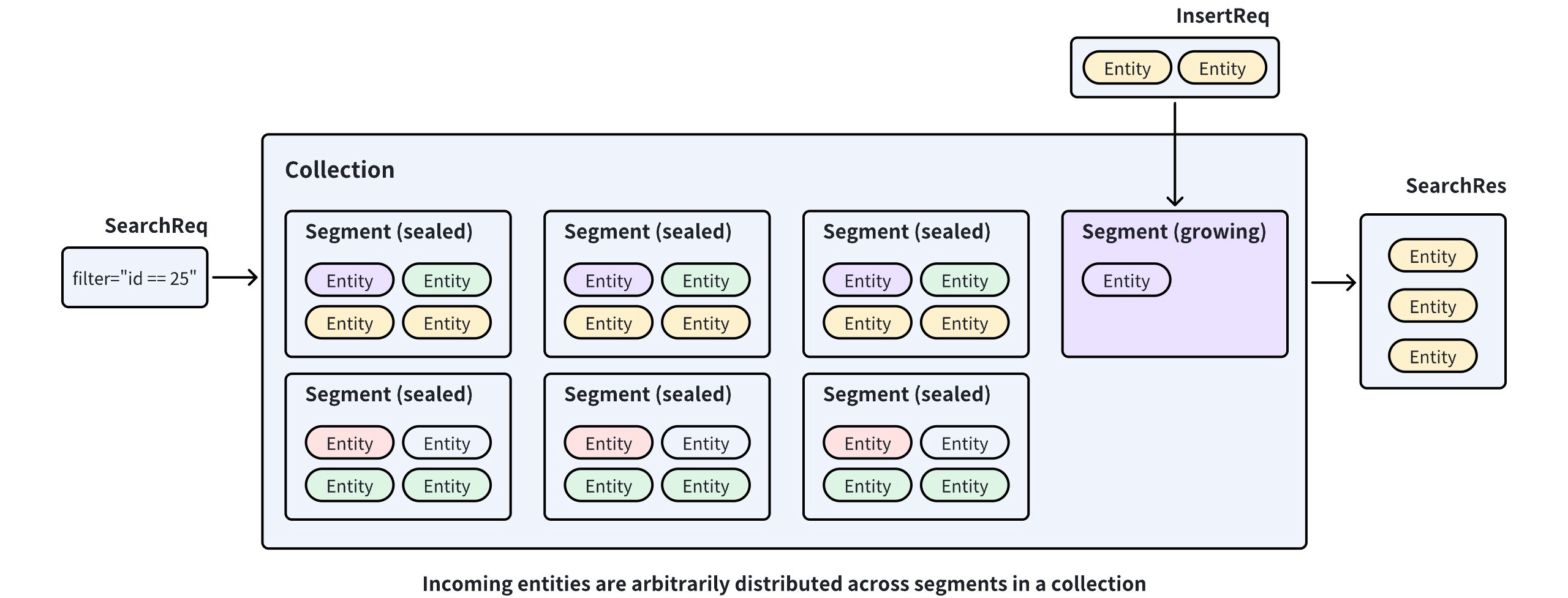
如果 Milvus 可以根据特定字段中的值在 segment 之间分发实体,搜索范围可以限制在一个 segment 内,从而提高搜索性能。
Clustering Compaction 是 Milvus 中的一项功能,它根据标量字段中的值重新分配 collection 中各 segment 之间的实体。要启用此功能,您首先需要选择一个标量字段作为 clustering key。这使 Milvus 能够在其 clustering key 值落在特定范围内时将实体重新分配到 segment 中。当您触发聚类压缩时,Milvus 生成/更新一个名为 PartitionStats 的全局索引,该索引记录 segment 与 clustering key 值之间的映射关系。
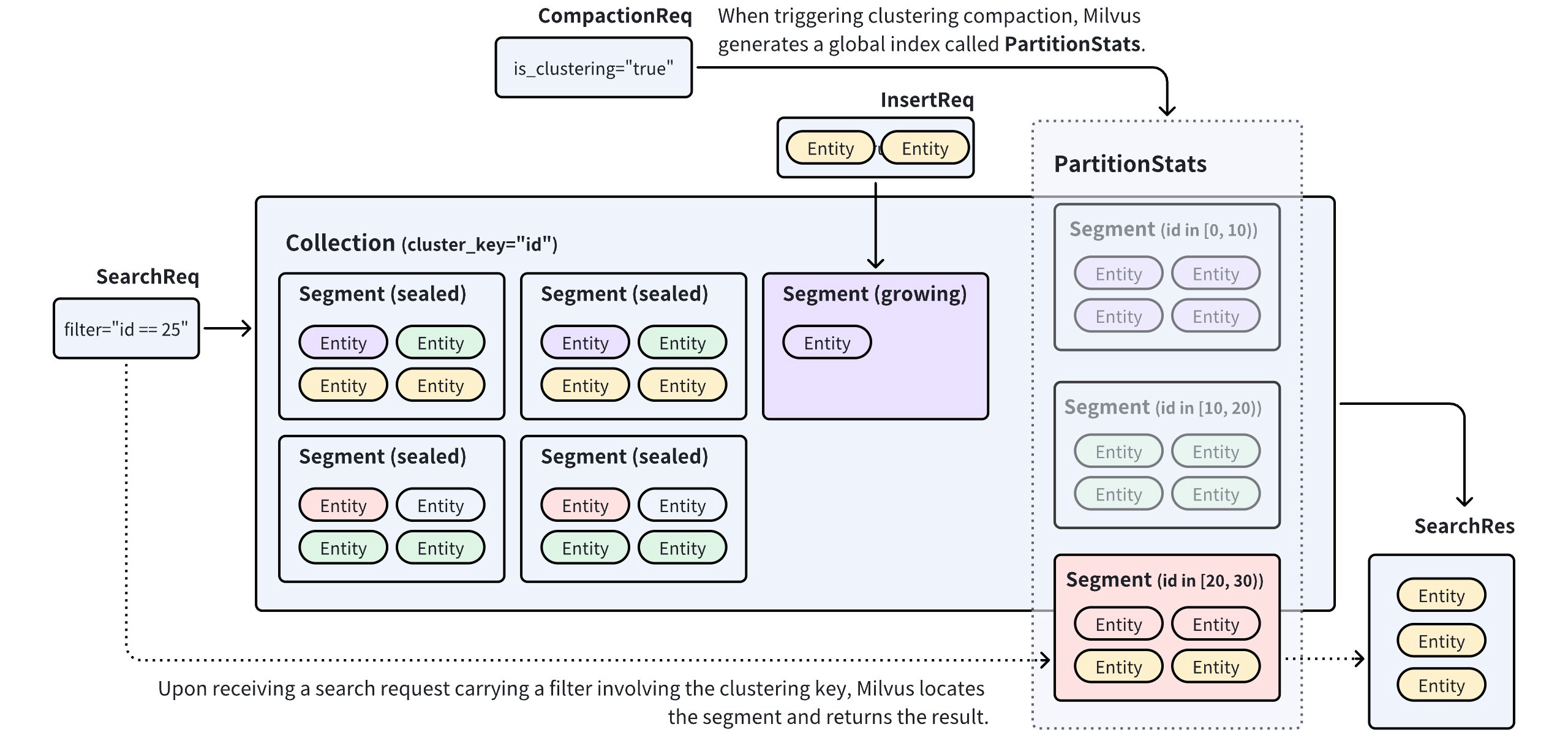
使用 PartitionStats 作为参考,Milvus 可以在接收到携带 clustering key 值的搜索/查询请求时剪除不相关数据,并将搜索范围限制在映射到该值的 segment 内,从而提高搜索性能。有关性能改进的详细信息,请参阅基准测试。
使用聚类压缩
Milvus 中的聚类压缩功能高度可配置。您可以选择手动触发它或设置为由 Milvus 定期自动触发。要启用聚类压缩,请执行以下操作:
全局配置
您需要如下所示修改 Milvus 配置文件。
dataCoord:
compaction:
clustering:
enable: true
autoEnable: false
triggerInterval: 600
minInterval: 3600
maxInterval: 259200
newDataSizeThreshold: 512m
timeout: 7200
queryNode:
enableSegmentPrune: true
datanode:
clusteringCompaction:
memoryBufferRatio: 0.1
workPoolSize: 8
common:
usePartitionKeyAsClusteringKey: true
配置项 | 描述 | 默认值 |
|---|---|---|
| ||
| 指定是否启用聚类压缩。如果需要为每个具有 clustering key 的 collection 启用此功能,请将此设置为 | false |
| 指定是否启用自动触发的压缩。将此设置为 | false |
| 指定 Milvus 启动聚类压缩的间隔(毫秒)。仅当您将 | |
| 指定最小间隔(毫秒)。仅当您将 将此设置为大于 | |
| 指定最大间隔(毫秒)。仅当您将 一旦 Milvus 检测到 collection 未进行聚类压缩的持续时间超过此值,它将强制执行聚类压缩。 | |
| 指定触发聚类压缩的上限阈值。仅当您将 一旦 Milvus 检测到 collection 中的数据量超过此值,它就会启动聚类压缩过程。 | |
| 指定聚类压缩的超时持续时间。如果执行时间超过此值,聚类压缩将失败。 | |
| ||
| 指定 Milvus 在接收搜索/查询请求时是否通过引用 PartitionStats 来剪除数据。将此设置为 | |
| ||
| 指定聚类压缩任务的内存缓冲区比率。当数据大小超过使用此比率计算的分配缓冲区大小时,Milvus 刷新数据。 | |
| 指定聚类压缩任务的工作池大小。 | |
| ||
| 指定是否在 collection 中使用 partition key 作为 clustering key。将此设置为 true 使 Milvus 将 collection 中的 partition key 视为 clustering key。 您始终可以通过显式设置 clustering key 来覆盖 collection 中的此设置。 | |
要将上述更改应用到您的 Milvus 集群,请遵循使用 Helm 配置 Milvus 和使用 Milvus Operators 配置 Milvus 中的步骤。
Collection 配置
对于特定 collection 中的聚类压缩,您应该从 collection 中选择一个标量字段作为 clustering key。
from pymilvus import MilvusClient, DataType
CLUSTER_ENDPOINT="http://localhost:19530"
TOKEN="root:Milvus"
client = MilvusClient(
uri=CLUSTER_ENDPOINT,
token=TOKEN
)
schema = MilvusClient.create_schema()
schema.add_field("id", DataType.INT64, is_primary=True, auto_id=False)
schema.add_field("key", DataType.INT64, is_clustering_key=True)
schema.add_field("var", DataType.VARCHAR, max_length=1000)
schema.add_field("vector", DataType.FLOAT_VECTOR, dim=5)
client.create_collection(
collection_name="clustering_test",
schema=schema
)
import io.milvus.v2.client.ConnectConfig;
import io.milvus.v2.client.MilvusClientV2;
import io.milvus.v2.common.DataType;
import io.milvus.v2.service.collection.request.AddFieldReq;
import io.milvus.v2.service.collection.request.CreateCollectionReq;
MilvusClientV2 client = new MilvusClientV2(ConnectConfig.builder()
.uri("http://localhost:19530")
.token("root:Milvus")
.build());
CreateCollectionReq.CollectionSchema schema = client.createSchema();
schema.addField(AddFieldReq.builder()
.fieldName("id")
.dataType(DataType.Int64)
.isPrimaryKey(true)
.autoID(false)
.build());
schema.addField(AddFieldReq.builder()
.fieldName("key")
.dataType(DataType.Int64)
.isClusteringKey(true)
.build());
schema.addField(AddFieldReq.builder()
.fieldName("var")
.dataType(DataType.VarChar)
.maxLength(1000)
.build());
schema.addField(AddFieldReq.builder()
.fieldName("vector")
.dataType(DataType.FloatVector)
.dimension(5)
.build());
CreateCollectionReq requestCreate = CreateCollectionReq.builder()
.collectionName("clustering_test")
.collectionSchema(schema)
.build();
client.createCollection(requestCreate);
// go
import { MilvusClient, DataType } from '@zilliz/milvus2-sdk-node';
const CLUSTER_ENDPOINT = 'http://localhost:19530';
const TOKEN = 'root:Milvus';
const client = new MilvusClient({
address: CLUSTER_ENDPOINT,
token: TOKEN,
});
const schema = [
{
name: 'id',
type: DataType.Int64,
is_primary_key: true,
autoID: false,
},
{
name: 'key',
type: DataType.Int64,
is_clustering_key: true,
},
{
name: 'var',
type: DataType.VarChar,
max_length: 1000,
is_primary_key: false,
},
{
name: 'vector',
type: DataType.FloatVector,
dim: 5,
},
];
await client.createCollection({
collection_name: 'clustering_test',
schema: schema,
});
# restful
您可以使用以下数据类型的标量字段作为 clustering key:Int8、Int16、Int32、Int64、Float、Double 和 VarChar。
触发聚类压缩
如果您已启用自动聚类压缩,Milvus 会在指定间隔自动触发压缩。或者,您可以手动触发压缩,如下所示:
# trigger a manual compaction
job_id = client.compact(
collection_name="clustering_test",
is_clustering=True
)
# get the compaction state
client.get_compaction_state(
job_id=job_id,
)
import io.milvus.v2.service.utility.request.CompactReq;
import io.milvus.v2.service.utility.request.GetCompactionStateReq;
import io.milvus.v2.service.utility.response.CompactResp;
import io.milvus.v2.service.utility.response.GetCompactionStateResp;
CompactResp compactResp = client.compact(CompactReq.builder()
.collectionName("clustering_test")
.isClustering(true)
.build());
GetCompactionStateResp stateResp = client.getCompactionState(GetCompactionStateReq.builder()
.compactionID(compactResp.getCompactionID())
.build());
System.out.println(stateResp.getState());
// go
// trigger a manual compaction
const {compactionID} = await client.compact({
collection_name: "clustering_test",
is_clustering: true
});
// get the compaction state
await client.getCompactionState({
compactionID: compactionID,
});
# restful
基准测试
数据量和查询模式的组合决定了聚类压缩可以带来的性能改进。内部基准测试表明,聚类压缩可使每秒查询数(QPS)提高多达 25 倍。
基准测试是在包含来自 2000 万、768 维 LAION 数据集实体的 collection 上进行的,其中 key 字段被指定为 clustering key。在 collection 中触发聚类压缩后,发送并发搜索直到 CPU 使用率达到高水位。
搜索过滤器 | 剪除比率 | 延迟 | 请求/秒 | ||||
|---|---|---|---|---|---|---|---|
平均值 | 最小值 | 最大值 | 中位数 | TP99 | |||
N/A | 0% | 1685 | 672 | 2294 | 1710 | 2291 | 17.75 |
key>200 and key < 800 | 40.2% | 1045 | 47 | 1828 | 1085 | 1617 | 28.38 |
key>200 and key < 600 | 59.8% | 829 | 45 | 1483 | 882 | 1303 | 35.78 |
key>200 and key < 400 | 79.5% | 550 | 100 | 985 | 584 | 898 | 54.00 |
key==1000 | 99% | 68 | 24 | 1273 | 70 | 246 | 431.41 |
随着搜索过滤器中搜索范围的缩小,剪除比率增加。这意味着在搜索过程中跳过了更多实体。当比较第一行和最后一行的统计数据时,您可以看到没有聚类压缩的搜索需要扫描整个 collection。另一方面,使用特定 key 进行聚类压缩的搜索可以实现高达 25 倍的改进。
最佳实践
以下是一些高效使用聚类压缩的技巧:
-
为具有大数据量的 collection 启用此功能。
搜索性能随着 collection 中数据量的增加而提高。为超过 100 万个实体的 collection 启用此功能是一个不错的选择。
-
选择合适的 clustering key。
您可以使用通常用作过滤条件的标量字段作为 clustering key。对于保存来自多个租户数据的 collection,您可以使用区分一个租户与另一个租户的字段作为 clustering key。
-
使用 partition key 作为 clustering key。
如果您想为 Milvus 实例中的所有 collection 启用此功能,或者在具有 partition key 的大型 collection 中仍然面临性能问题,您可以将
common.usePartitionKeyAsClusteringKey设置为true。通过这样做,当您在 collection 中选择标量字段作为 partition key 时,您将拥有一个 clustering key 和一个 partition key。请注意,此设置不会阻止您选择另一个标量字段作为 clustering key。显式指定的 clustering key 始终具有优先权。