分组搜索
分组搜索允许 Milvus 按指定字段的值对搜索结果进行分组,从而在更高层次上聚合数据。例如,您可以使用基本的 ANN 搜索来查找与手头书籍相似的书籍,但您可以使用分组搜索来查找可能涉及该书中讨论话题的书籍类别。本主题描述如何使用分组搜索以及关键注意事项。
概述
当搜索结果中的实体在标量字段中共享相同值时,这表明它们在特定属性上相似,这可能会对搜索结果产生负面影响。
假设一个 collection 存储多个文档(由 docId 表示)。为了在将文档转换为向量时保留尽可能多的语义信息,每个文档被分割成更小、可管理的段落(或 chunks)并存储为单独的实体。即使文档被分割成较小的部分,用户通常仍然有兴趣识别哪些文档与他们的需求最相关。
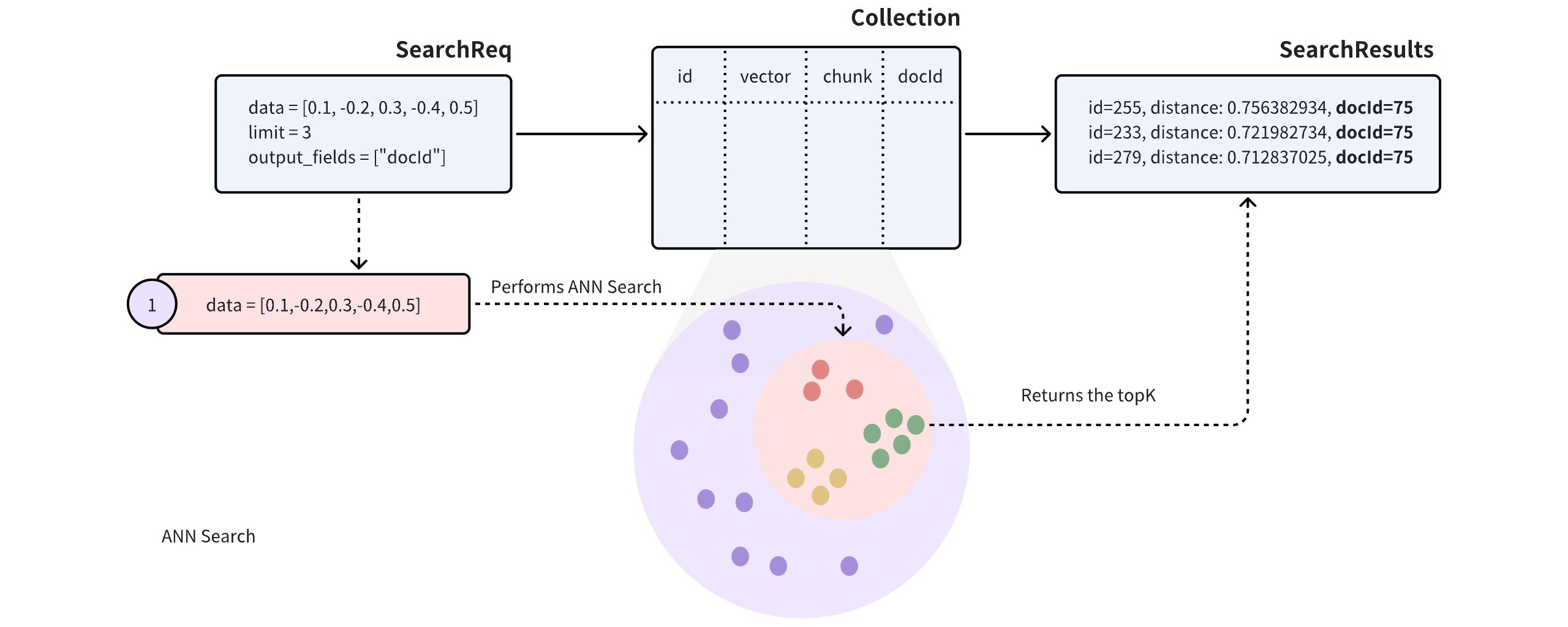
在此类 collection 上执行近似最近邻(ANN)搜索时,搜索结果可能包含来自同一文档的多个段落,可能导致其他文档被忽视,这可能不符合预期的用例。
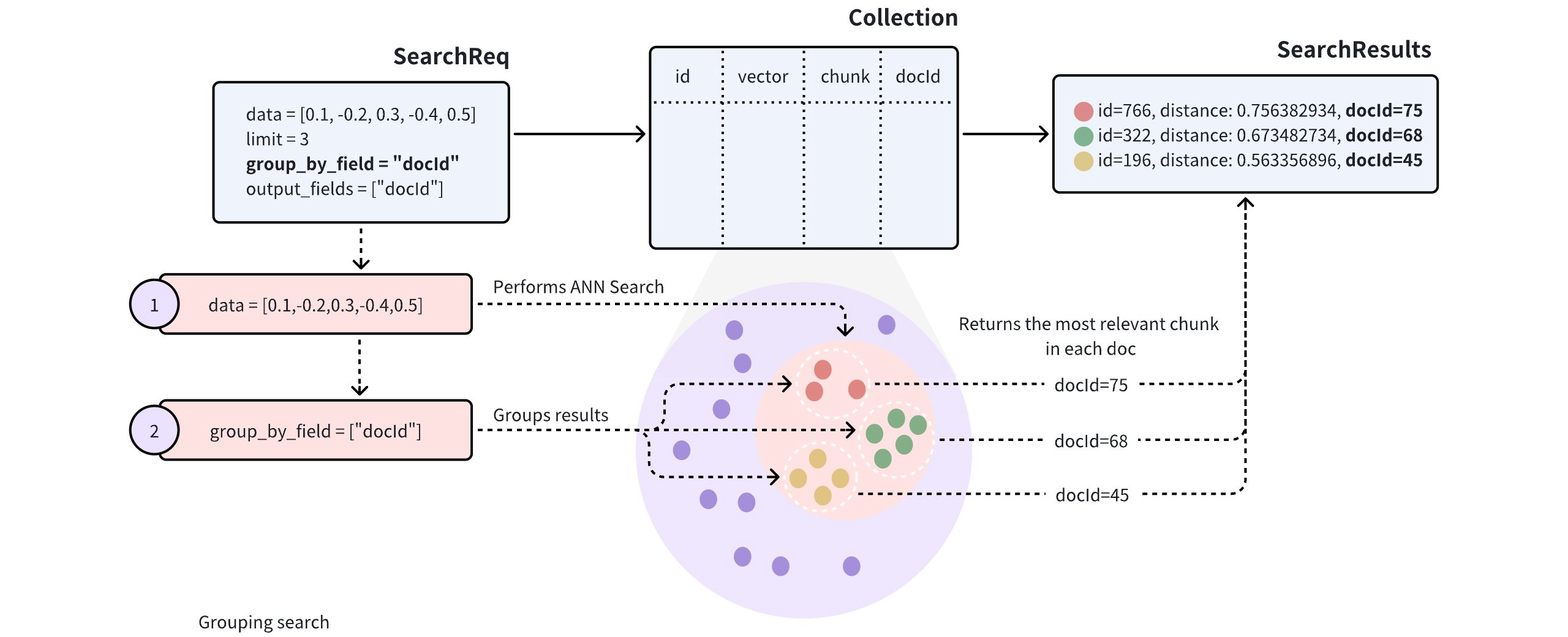
为了提高搜索结果的多样性,您可以在搜索请求中添加 group_by_field 参数来启用分组搜索。如图所示,您可以将 group_by_field 设置为 docId。收到此请求后,Milvus 将:
-
基于提供的查询向量执行 ANN 搜索,找到与查询最相似的所有实体。
-
按指定的
group_by_field(如docId)对搜索结果进行分组。 -
返回每个组的顶部结果,由
limit参数定义,每个组中最相似的实体。
上述请求中,limit=3 表示系统将返回来自三个组的搜索结果,每个组包含与查询向量最相似的单个 entity。
配置分组大小
默认情况下,分组搜索每组只返回一个 entity。如果您希望每组返回多个结果,请调整 group_size 和 strict_group_size 参数。
from pymilvus import MilvusClient
client = MilvusClient(
uri="http://localhost:19530",
token="root:Milvus"
)
query_vectors = [
[0.14529211512077012, 0.9147257273453546, 0.7965055218724449, 0.7009258593102812, 0.5605206522382088]]
# Group search results
res = client.search(
collection_name="my_collection",
data=query_vectors,
limit=3,
group_by_field="docId",
output_fields=["docId"]
)
# Retrieve the values in the `docId` column
doc_ids = [result['entity']['docId'] for result in res[0]]
import io.milvus.v2.client.ConnectConfig;
import io.milvus.v2.client.MilvusClientV2;
import io.milvus.v2.service.vector.request.SearchReq
import io.milvus.v2.service.vector.request.data.FloatVec;
import io.milvus.v2.service.vector.response.SearchResp
MilvusClientV2 client = new MilvusClientV2(ConnectConfig.builder()
.uri("http://localhost:19530")
.token("root:Milvus")
.build());
FloatVec queryVector = new FloatVec(new float[]{0.14529211512077012f, 0.9147257273453546f, 0.7965055218724449f, 0.7009258593102812f, 0.5605206522382088f});
SearchReq searchReq = SearchReq.builder()
.collectionName("my_collection")
.data(Collections.singletonList(queryVector))
.topK(3)
.groupByFieldName("docId")
.outputFields(Collections.singletonList("docId"))
.build();
SearchResp searchResp = client.search(searchReq);
List<List<SearchResp.SearchResult>> searchResults = searchResp.getSearchResults();
for (List<SearchResp.SearchResult> results : searchResults) {
System.out.println("TopK results:");
for (SearchResp.SearchResult result : results) {
System.out.println(result);
}
}
// Output
// TopK results:
// SearchResp.SearchResult(entity={docId=5}, score=0.74767184, id=1)
// SearchResp.SearchResult(entity={docId=2}, score=0.6254269, id=7)
// SearchResp.SearchResult(entity={docId=3}, score=0.3611898, id=3)
import (
"context"
"fmt"
"github.com/milvus-io/milvus/client/v2/entity"
"github.com/milvus-io/milvus/client/v2/milvusclient"
)
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
milvusAddr := "localhost:19530"
client, err := milvusclient.New(ctx, &milvusclient.ClientConfig{
Address: milvusAddr,
})
if err != nil {
fmt.Println(err.Error())
// handle error
}
defer client.Close(ctx)
queryVector := []float32{0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592}
resultSets, err := client.Search(ctx, milvusclient.NewSearchOption(
"my_collection", // collectionName
3, // limit
[]entity.Vector{entity.FloatVector(queryVector)},
).WithANNSField("vector").
WithGroupByField("docId").
WithOutputFields("docId"))
if err != nil {
fmt.Println(err.Error())
// handle error
}
for _, resultSet := range resultSets {
fmt.Println("IDs: ", resultSet.IDs.FieldData().GetScalars())
fmt.Println("Scores: ", resultSet.Scores)
fmt.Println("docId: ", resultSet.GetColumn("docId").FieldData().GetScalars())
}
import { MilvusClient, DataType } from "@zilliz/milvus2-sdk-node";
const address = "http://localhost:19530";
const token = "root:Milvus";
const client = new MilvusClient({address, token});
var query_vector = [0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592]
res = await client.search({
collection_name: "my_collection",
data: [query_vector],
limit: 3,
group_by_field: "docId"
})
// Retrieve the values in the `docId` column
var docIds = res.results.map(result => result.entity.docId)
export CLUSTER_ENDPOINT="http://localhost:19530"
export TOKEN="root:Milvus"
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/entities/search" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
-d '{
"collectionName": "my_collection",
"data": [
[0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592]
],
"annsField": "vector",
"limit": 3,
"groupingField": "docId",
"outputFields": ["docId"]
}'
Configure group size
By default, Grouping Search returns only one entity per group. If you want multiple results per group, adjust the group_size and strict_group_size parameters.
# Group search results
res = client.search(
collection_name="my_collection",
data=query_vectors, # query vector
limit=5, # number of groups to return
group_by_field="docId", # grouping field
group_size=2, # p to 2 entities to return from each group
strict_group_size=True, # return exact 2 entities from each group
output_fields=["docId"]
)
FloatVec queryVector = new FloatVec(new float[]{0.14529211512077012f, 0.9147257273453546f, 0.7965055218724449f, 0.7009258593102812f, 0.5605206522382088f});
SearchReq searchReq = SearchReq.builder()
.collectionName("my_collection")
.data(Collections.singletonList(queryVector))
.topK(5)
.groupByFieldName("docId")
.groupSize(2)
.strictGroupSize(true)
.outputFields(Collections.singletonList("docId"))
.build();
SearchResp searchResp = client.search(searchReq);
List<List<SearchResp.SearchResult>> searchResults = searchResp.getSearchResults();
for (List<SearchResp.SearchResult> results : searchResults) {
System.out.println("TopK results:");
for (SearchResp.SearchResult result : results) {
System.out.println(result);
}
}
// Output
// TopK results:
// SearchResp.SearchResult(entity={docId=5}, score=0.74767184, id=1)
// SearchResp.SearchResult(entity={docId=5}, score=-0.49148706, id=8)
// SearchResp.SearchResult(entity={docId=2}, score=0.6254269, id=7)
// SearchResp.SearchResult(entity={docId=2}, score=0.38515577, id=2)
// SearchResp.SearchResult(entity={docId=3}, score=0.3611898, id=3)
// SearchResp.SearchResult(entity={docId=3}, score=0.19556211, id=4)
import (
"context"
"fmt"
"github.com/milvus-io/milvus/client/v2/entity"
"github.com/milvus-io/milvus/client/v2/milvusclient"
)
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
milvusAddr := "localhost:19530"
client, err := milvusclient.New(ctx, &milvusclient.ClientConfig{
Address: milvusAddr,
})
if err != nil {
fmt.Println(err.Error())
// handle error
}
defer client.Close(ctx)
queryVector := []float32{0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592}
resultSets, err := client.Search(ctx, milvusclient.NewSearchOption(
"my_collection", // collectionName
5, // limit
[]entity.Vector{entity.FloatVector(queryVector)},
).WithANNSField("vector").
WithGroupByField("docId").
WithStrictGroupSize(true).
WithGroupSize(2).
WithOutputFields("docId"))
if err != nil {
fmt.Println(err.Error())
// handle error
}
for _, resultSet := range resultSets {
fmt.Println("IDs: ", resultSet.IDs.FieldData().GetScalars())
fmt.Println("Scores: ", resultSet.Scores)
fmt.Println("docId: ", resultSet.GetColumn("docId").FieldData().GetScalars())
}
import { MilvusClient, DataType } from "@zilliz/milvus2-sdk-node";
const address = "http://localhost:19530";
const token = "root:Milvus";
const client = new MilvusClient({address, token});
var query_vector = [0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592]
res = await client.search({
collection_name: "my_collection",
data: [query_vector],
limit: 5,
group_by_field: "docId",
group_size: 2,
strict_group_size: true
})
// Retrieve the values in the `docId` column
var docIds = res.results.map(result => result.entity.docId)
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/entities/search" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
-d '{
"collectionName": "my_collection",
"data": [
[0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592]
],
"annsField": "vector",
"limit": 5,
"groupingField": "docId",
"groupSize":2,
"strictGroupSize":true,
"outputFields": ["docId"]
}'
在上述示例中:
-
group_size:指定每组返回的所需 entity 数量。例如,设置group_size=2意味着每组(或每个docId)理想情况下应返回两个最相似的段落(或 chunks)。如果未设置group_size,系统默认为每组返回一个结果。 -
strict_group_size:这是一个布尔参数,用于控制系统是否应严格执行group_size设置的计数。当strict_group_size=True时,系统将尝试在每组中包含group_size指定的确切 entity 数量,除非该组中没有足够的数据。默认情况下(strict_group_size=False),系统优先满足limit参数指定的组数,而不是确保每组包含group_size个 entity。在数据分布不均的情况下,这种方法通常更高效。
有关其他参数详细信息,请参阅搜索。
注意事项
-
索引:此分组功能仅适用于使用以下 index 类型建立索引的 collection:FLAT、IVF_FLAT、IVF_SQ8、HNSW、HNSW_PQ、HNSW_PRQ、HNSW_SQ、DISKANN、SPARSE_INVERTED_INDEX。
-
组数:
limit参数控制返回搜索结果的组数,而不是每组内 entity 的具体数量。设置适当的limit有助于控制搜索多样性和查询性能。如果数据分布密集或性能是关注点,减少limit可以降低计算成本。 -
每组 entity 数:
group_size参数控制每组返回的 entity 数量。根据您的用例调整group_size可以增加搜索结果的丰富性。但是,如果数据分布不均,某些组返回的 entity 可能少于group_size指定的数量,特别是在数据有限的场景中。 -
严格分组大小:当
strict_group_size=True时,系统将尝试为每组返回指定数量的 entity(group_size),除非该组中没有足够的数据。此设置确保每组的 entity 计数一致,但在数据分布不均或资源有限的情况下可能导致性能下降。如果不需要严格的 entity 计数,设置strict_group_size=False可以提高查询速度。
搜索参数
在分组搜索中,您还可以使用特定搜索参数来优化搜索过程。这些参数与您在常规搜索中使用的参数相同。有关详细信息,请参阅搜索参数。
限制
- 嵌套分组:不支持嵌套分组或多字段分组。
- 分片支持:分组搜索不能用于包含多个分片的 collection。
- 参数限制:某些搜索参数可能与分组搜索不兼容。确保您选择的参数与分组搜索功能兼容。