度量类型
相似性度量用于测量向量之间的相似性。选择适当的距离度量有助于显著提高分类和聚类性能。
目前,Milvus 支持以下类型的相似性度量:欧几里得距离(L2)、内积(IP)、余弦相似度(COSINE)、JACCARD、HAMMING 和 BM25(专为稀疏向量的全文搜索设计)。
下表总结了不同 field 类型与其对应度量类型之间的映射关系。
Field 类型 | 维度范围 | 支持的度量类型 | 默认度量类型 |
|---|---|---|---|
| 2-32,768 |
|
|
| 2-32,768 |
|
|
| 2-32,768 |
|
|
| 无需指定维度。 |
|
|
| 8-32,768*8 |
|
|
-
对于
SPARSE_FLOAT_VECTOR类型的向量 field,仅在执行全文搜索时使用BM25度量类型。有关更多信息,请参阅全文搜索。 -
对于
BINARY_VECTOR类型的向量 field,维度值(dim)必须是 8 的倍数。
下表总结了所有支持的度量类型的相似性距离值特征及其值范围。
度量类型 | 相似性距离值特征 | 相似性距离值范围 |
|---|---|---|
| 值越小表示相似性越大。 | [0, ∞) |
| 值越大表示相似性越大。 | [-1, 1] |
| 值越大表示相似性越大。 | [-1, 1] |
| 值越小表示相似性越大。 | [0, 1] |
| 值越小表示相似性越大。 | [0, dim(vector)] |
| 基于词频、逆文档频率和文档规范化评分相关性。 | [0, ∞) |
欧几里得距离(L2)
本质上,欧几里得距离测量连接两个点的线段的长度。
欧几里得距离的公式如下:
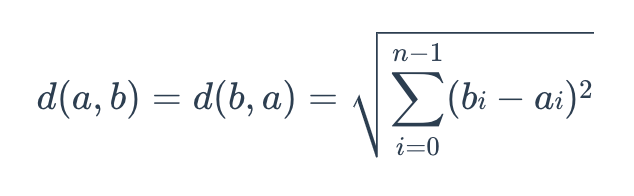
其中 a = (a0, a1,..., an-1) 和 b = (b0, b1,..., bn-1) 是 n 维欧几里得空间中的两个点。
这是最常用的距离度量,在数据连续时非常有用。
当选择欧几里得距离作为距离度量时,Milvus 只计算应用平方根之前的值。
内积(IP)
两个嵌入之间的 IP 距离定义如下:
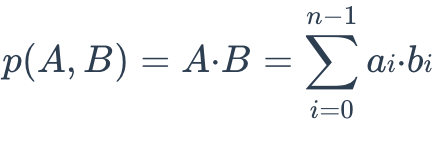
如果您需要比较未归一化的数据或关心幅度和角度时,IP 更有用。
如果您使用 IP 计算嵌入之间的相似性,您必须归一化您的嵌入。归一化后,内积等于余弦相似度。
假设 X' 是从嵌入 X 归一化得到的:
![]()
两个嵌入之间的相关性如下:

余弦相似度
余弦相似度使用两组向量之间角度的余弦来测量它们的相似程度。您可以将两组向量视为从同一点开始的线段,例如 [0,0,...],但指向不同方向。
要计算两组向量 A = (a0, a1,..., an-1) 和 B = (b0, b1,..., bn-1) 之间的余弦相似度,使用以下公式:
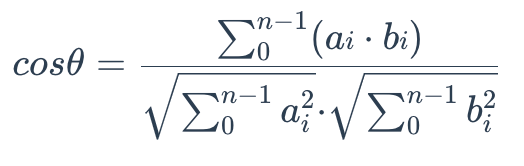
余弦相似度始终在区间 [-1, 1] 内。例如,两个成比例的向量的余弦相似度为 1,两个正交向量的相似度为 0,两个相反向量的相似度为 -1。余弦越大,两个向量之间的角度越小,表明这两个向量彼此更相似。
通过从 1 中减去它们的余弦相似度,您可以得到两个向量之间的余弦距离。
JACCARD 距离
JACCARD 相似系数测量两个样本集之间的相似性,定义为定义集合的交集的基数除以它们的并集的基数。它只能应用于有限样本集。

JACCARD 距离测量数据集之间的不相似性,通过从 1 中减去 JACCARD 相似系数得到。对于二进制变量,JACCARD 距离等价于 Tanimoto 系数。

HAMMING 距离
HAMMING 距离测量二进制数据字符串。等长两个字符串之间的距离是位不同的位位置数。
例如,假设有两个字符串,1101 1001 和 1001 1101。
11011001 ⊕ 10011101 = 01000100。由于这包含两个 1,所以 HAMMING 距离 d (11011001, 10011101) = 2。
BM25 相似度
BM25 是一种广泛使用的文本相关性测量方法,专为全文搜索设计。它结合了以下三个关键因素:
-
词频(TF): 测量词在文档中出现的频率。虽然更高的频率通常表示更大的重要性,但 BM25 使用饱和参数 k₁ 来防止过于频繁的词主导相关性分数。
-
逆文档频率(IDF): 反映词在整个语料库中的重要性。在较少文档中出现的词获得更高的 IDF 值,表明对相关性的贡献更大。
-
文档长度规范化: 较长的文档往往由于包含更多词而得分更高。BM25 通过规范化文档长度来减轻这种偏差,参数 b 控制这种规范化的强度。
BM25 评分计算如下:
score(D, Q) = ∑[i=1 to n] IDF(qi) × [TF(qi,D) × (k1+1)] / [TF(qi,D) + k1 × (1-b + b × |D|/avgdl)]
参数说明:
-
Q:用户提供的查询文本。
-
D:正在评估的文档。
-
TF(qi, D):词频,表示词 qi 在文档 D 中出现的次数。
-
IDF(qi):逆文档频率,计算如下:
IDF(qi) = log((N - n(qi) + 0.5) / (n(qi) + 0.5) + 1)其中 N 是语料库中文档的总数,n(qi) 是包含词 qi 的文档数。
-
|D|:文档 D 的长度(词的总数)。
-
avgdl:语料库中所有文档的平均长度。
-
k1:控制词频对分数的影响。较高的值增加词频的重要性。典型范围是 [1.2, 2.0],而 Milvus 允许的范围是 [0, 3]。
-
b:控制长度规范化的程度,范围从 0 到 1。当值为 0 时,不应用规范化;当值为 1 时,应用完全规范化。